21.05.25
Machine Learning
@과대or과소 적합

과대 적합 : 훈련 데이터에 너무 잘맞아버려서 일반성이 떨어지는 것 ( = 복잡도가 높은 모델 을 만든 것. )
-> Train Data에 너무 적응 해버려서 Test Data에서 높은 성능을 보여줄 수 없다.
-> Train Data 이외의 다양한 변수에 대응하기 힘들다. ( = 새로운 데이터에 대응할 수 없다 . )
예로 주어진 학습(Train) 데이터에서 만든 모델에 대한 성능을 올리기 위해 여러 규칙을 만들었다. ( 복잡도 증가 )
"A는 1보다 높고..", "B는 모두 Yes이며..", "C는 no인 경우.." 이런식으로 규칙을 늘린다면 성능은 높아질 것이다.
단, Train Data 한정 해서. 때문에, 새로운 데이터( Test 데이터나 )에는 높은 성능(정확도)을 보여주지 못할것이다.
과소 적합 : 과대 적합과 반대의 상황, 너무 단순한 모델을 만드는 것 .
예로 단순하게 "A가 True면 된다." 연관 없이 적은 규칙 하나만을 갖는 모델을 만들어 버리면
다양성도 잡을 수 없고 , Train Data를 포함해 다른 Data들에서도 낮은 성능 을 보일 것이다.
이 2가지의 경우를 해결할 수 있는 방법
중 하나는 복잡도에 대한 "규제"를 설정하는 것이다.
다른 경우로 모델이 새로운 데이터에 대해 정확히 예측하는 경우 를 훈련 세트에서 테스트 세트로 일반화 ( Generalization )되었다고 한다.
@하이퍼파라미터 - 규제
Hyperparameter ( 하이퍼파라미터 ) : 머신러닝에서 최적의 훈련 모델을 구현하기 위한 모델 설정 변수
- 학습 알고리즘의 샘플에 대한 일반화를 위해 조절 된다.
- Parameter와 비슷한 개념이나, 모델의 최적의 학습을 위한 "규제" 설정을 위한 변수이다.
@K-fold cross-Validation ( 교차 검증 ) - 모델 평가 개선 및 성능 향상
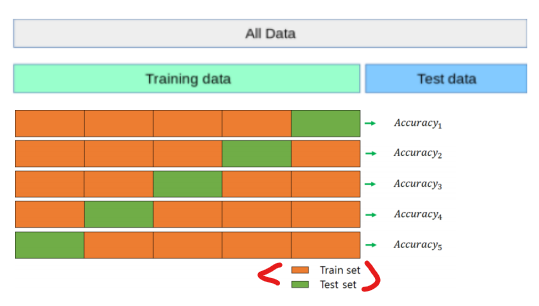
=> 검증 데이터를 하나로 고정하지 않고, Train 데이터의 모든 부분을 사용한다 .
위에서 언급한 과대적합과 같은 모델 설정 이상을 해결하는 방법 중 하나이다.
교차검증의 과정은 아래와 같은 순서로 이루어진다.
- Train 데이터를 k개의 그룹으로 나눈다
- K-1개의 그룹을 학습에 사용한다.
- 나머지 1개의 그룹을 이용해서 평가를 수행한다.
- 2번, 3번 과정을 k번 반복한다.
- 모든 결과의 평균을 구한다. -> 위험도를 낮춘다.
( 모델 평가 -> 데이터를 학습시키는 방법이 좋기 전에 주어진 모델이 잘못됐다면 원할학 작업이 수행되기 힘듬
때문에, 모델 평가하는 작업이 필요한것. ) => 과대 or 과소 적합의 위험성 줄이기 .
아래는 교차검증의 동작 방법 및 장단점에 대한 내용.


@교차 검증 - 실습
% 용어 정리 - 적합 제어

위 사진에서 검은색 글씨는 해당 제어에 대한 정의 이며, 노란 글씨는 해당 제어를 주어야 하는 경우이다.
- max_depth : 뻗어나가는 가지의 길이라고 생각하면 된다. 즉 경우의 수가 올라가는 것.
- min_samples_split : 각 경우(노드)가 분할하기 전에 갖고 있어야 할 샘플 수 이다. 즉, 특정 경우에 대한 샘플의 수가 제한된 최소 샘플 수를 채우지 못하면 분할하지 못하게 한다.
- min_samples_leaf : min_samples_split과 비슷한데, leaf 노드가 가져야 할 최소 샘플 수 이다.
- max_leaf_nodes : 리프 노드가 가질 수 있는 샘플의 최대 갯수.

- 위는 Decision Tree를 만들었을 경우 각 노드의 명칭에 대한 예시이다.
% 실습
주어진 데이터는 버섯에 대한 정보로 X는 버섯의 정보 , y는 버섯의 이름을 담고 있다 .

- "cross_val_score"는 교차검증을 수행할 수 있게 해주는 Library이다.
- tree_model4 에 노드 최소 분할 수를 지정, Decision Tree를 생성한다 . / fit 명령어를 이용하여 데이터를 학습.
- X_train 은, 특정 데이터의 각 행에 대한 정보들을 담고 있는 DF를 one-hot Encoding한 결과이다.
- X_train이 정보를 담고 있다면, y_train 은 해당 정보에 대한 답을 담고있는 데이터이다.
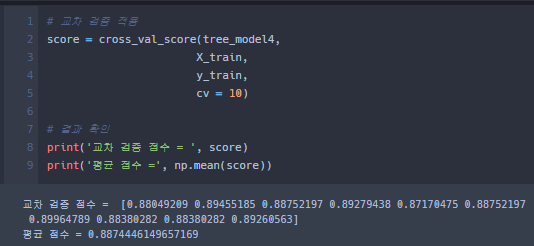
- 생성한 모델 train_model4를 교차검증 명령어 cross_val_score 에 넣어 결과를 확인한다.
- 교차 검증하는데 있어 몇개의 그룹으로 나누는지에 해당하는(즉, K를 말한다. )옵션은 "cv"이다.
- 생성한 모델, 학습데이터, 샘플, K의 갯수(Default=5)를 기입 해당 결과의 성능을 score에 담아 확인.
- numpy 함수의 평균 함수를 이용해 해당 성능을 확인할 수 있다.
교차검증 명령어의 옵션을 보면 알 수 있지만, 내가 주고자 하는 하이퍼파라미터를 하나씩 지정해줄 수 있다.
@GridSerchCV를 이용한 모델의 성능 개선
- sklearn 라이브러리에서 제공해주는 모델 성능 개선 함수
- 사용자가 모델과 Hyper-Parameter들을 지정
- 사용자가 설정해준것에 따라 교차검증까지 수행해준다. ( 교차검증을 개선한 방법 )
- GridSearchCV 순차적으로 Hyper-Parameter들을 변경해가면서 학습과 평가를 수행
- 가장 성능이 좋은 Hyper-Parameter를 제시
% GridSearchCV 사용법

- 교차검증을 가져온 함수와 동일한곳에서 "GridSearchCV"를 호출한다.
- 내가 지정할 하이퍼파라미터를 Dictionary 형태 로 준다.
- 각 하이퍼파라미터에 지정한 값들을 가지고 다른 HF들과 여러 조합을 만들어 학습. ( 최고의 조합을 찾아줌 )
- "model"의 경우는 교차검증 실습 때와 다르게 아무 "규제"가 없는 기본 모델을 부여 한다.
- "scoring"은 모델을 평가하는 방법으로, 'accuracy'라는걸 기준으로 사용한 것. (= 맞은갯수 / 전체갯수 단순하다. )
% 실습

- 위에서 언급했듯 HyperParameter를 딕셔너리 형태로, 모델은 기본으로 주었다.
- 그리고 "grid"라는 변수에 GridSearchCV 을 적용, "grid"에 학습데이터를 적용한 값을 "result7"에 담았다.
- 출력된 결과창을 보면 어떤 기법인지, HF는 뭔지, 등등의 정보를 출력한다.

- best_params_ 명령어는 내가 지정한 HF들의 각 값들에 대한 최고의 조합을 출력한다.
- best_score_ 는 bset_param을 사용한 최적의 성능을 출력한다.
- 성능의 값은 하나만 나오고, 교차검증으로 10번이 진행됐다. 이를 통해 평균값임을 알 수 있다.
위 방법을 기존의 교차검증 방법으로 구현해보았다.

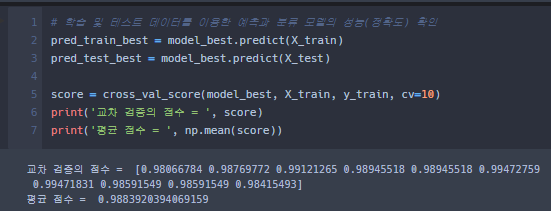
정리하면
- GridSearchCV 방법으로 Hyper Parameter들의 최적의 조합을 찾았다.
- 찾은 조합을 기반, 모델을 완성.
- 해당 모델을 교차 검증 방법을 통해 성능을 출력하였다.
- 해당 평균 성능이 GridSearchCV기법으로 찾은 성능의 값과 같음을 알 수 있다.
- 즉, GridSearchCV기법은 교차검증 보다 더욱 다양한 경우에서 최적의 성능을 찾을 수 있음 을 알 수 있다.
================================================
JSP
@JSP - 실습

위와 같은 실습을 위한 파일을 받았다. 받은 파일은 현재 HTML 코드만 완성되어있는 형태로 내가 실습할 것은
각 메뉴들, 창들에 대한 기능을 넣고, 연결하는 것 .
% 로그인 & 회원가입
- 로그인 및 회원가입하는 부분의 기능은 48일차에 했던 Model.1 실습과 동일하다.
- 요청 받은 값을 JDBC를 통해 생성한 Table에 삽입(회원가입), 조회(로그인)의 작업을 수행한다.
- 단, 다르게 진행한건 Login한 경우 해당 회원 정보를 세션으로 main파일에 전송 하였다.
- Table에 대한 VO (DTO)를 만들어 생성자를 세션 값으로 저장하였다 .


- "MemberVO"에서 생성한 생성자를 활용, Controller 에 속하는 로그인 서비스 파일에서 회원 정보를 vo라는 변수에 담는다.
- JSP와 다르게 Servlet 파일에서 session을 사용하려면 따로 호출 을 해줘야 한다. --> HttpSession .
- main.jsp 파일에서 session을 쓰기위해 이름은 "memver", 값은 vo로 지정한 session을 설정해준다.
% super( )
=> 부모 클래스의 생성자를 호출한다.
ex) super( A ) 라고 하면 A라는 클래스의 생성자를 호출하여 사용할 수 있다.
% main창에 회원정보 표기


- 로그인하지 않은 경우엔 좌측과 같은 문구가 뜨고, 로그인한 경우에는 우측과 같이 해당 회원의 정보를 표기한다.
- 해당 값을 위에서 언급했듯 "Session" 으로 받았기 때문에, 브라우저를 종료하게 되면 정보가 삭제된다 .
아래는 해당 부분에 대한 소스코드

- 빨간색 박스는 로그인하지 않은 경우(Session으로 값을 받아오지 못함 )이고, 보라색 박스는 로그인했을 때, Session 값인 VO라는 객체의 Getter를 활용 하여 가져왔다.


- main페이지에서 "vo" 변수에 Session 값을 가져온다.
- session.getAttribute(세션이름) 으로 특정 세션 값을 변수에 담았다.
- getAttribute로 가져온 값은 "Object" 형태 이므로 우리가 사용할 수 있도록 "MemberVO" 형태로 캐스팅 해준다.
'국비교육기관 > 수업' 카테고리의 다른 글
| 54일차 머신러닝 랜덤 포레스트 실습 / JSP 게시판페이지 (0) | 2021.05.27 |
|---|---|
| 53일차 머신러닝 - Importance, 시각화 / JSP - DAO 활용 페이지 실습 (0) | 2021.05.26 |
| 51일차_머신러닝_인코딩 실습_Decsion Tree / JSP_Scope (0) | 2021.05.24 |
| 50일차_머신러닝 / JSP_Session_Cookie_실습 (0) | 2021.05.22 |
| 49일차_JSP_MVC Model.1_쿠키 / 머신러닝_결측치_시각화 (0) | 2021.05.21 |




댓글