@21.04.01
JAVA
@While문
Java에서의 while문은 사용법은 파이썬과 큰 차이는 없다.
그저
- 콜론( : ) 대신 중괄호( {} )로 감싸 안의 내용을 반복
- 무한루프문의 True는 소문자로 true라 작성
- break문 동일
이정도??... 특별히 어려운건 없다. 다만 지역변수 관련해서만 좀 익히고 있자. 아래는 예제이다.
package java_fes;
import java.util.Scanner;
public class moon_01 {
public static void main(String[] args) {
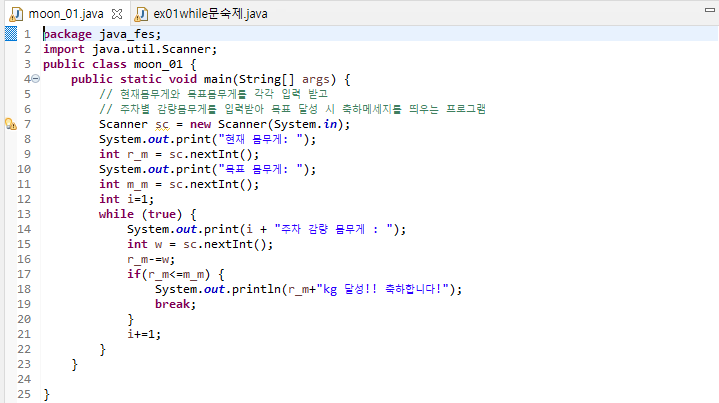
// 현재몸무게와 목표몸무게를 각각 입력 받고
// 주차별 감량몸무게를 입력받아 목표 달성 시 축하메세지를 띄우는 프로그램
Scanner sc = new Scanner(System.in);
System.out.print("현재 몸무게: ");
int r_m = sc.nextInt();
System.out.print("목표 몸무게: ");
int m_m = sc.nextInt();
int i=1;
while (true) {
System.out.print(i + "주차 감량 몸무게 : ");
int w = sc.nextInt();
r_m-=w;
if(r_m<=m_m) {
System.out.println(r_m+"kg 달성!! 축하합니다!");
break;
}
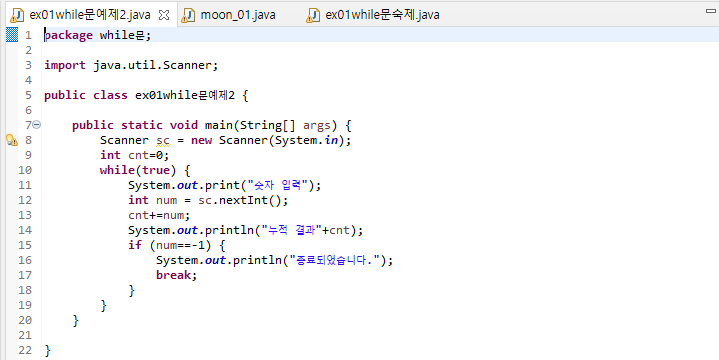
i+=1;}}}위의 와일문 안쪽을 보면 변수 r_m이라던가 m_m과 같은것들, 이를 반복문 안에서 선언해주면 While문 밖에서는 사용할 수 없다.
13일차에 나왔던 개념인 지역변수 확인할 것.
@for문에 대해
그냥 예제를 풀면서 느낀건데...
파이썬에서의 for문과 자바에서의 for문은 다르다.
간단한 예제를 예로 설명하자면
package java_fes;
public class moon_11 {
public static void main(String[] args) {
for(int i=0;i<10;i++) {
if(i%2==0) {
i+=1;}
System.out.println(i);}}}
위 코드의 결과가 뭐라고 생각하나? 당연히 파이썬 for문에의하면 10번 반복된다.
i의 값이 변동되지 않아야한다.
근데, 자바에서의 for문은 반복을 위한 임의 변수의 값을 변동하면 적용이 된다.
때문에 위의 결과는 아래처럼 나온다.


이클립스 스캔


================================================
웹크롤링
@긁어온멜론차트 DF만들기
import request as req
from bs4 import BeautifulSoup as bs
import pandas as pd
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"}
res = req.get("https://www.melon.com/chart/index.htm", headers = head)
#1==========================================================================================
cha = bs(res.text, "html.parser")
chart = cha.find_all("span", class_ = "checkEllipsis")
chart_m = cha.find_all("div", class_ = "ellipsis rank01")
#2==========================================================================================
rank_li = []
song_li = []
art_li = []
for i in range(len(chart)):
rank_li.append(i+1)
song_li.append(chart[i].text)
art_li.append(chart_m[i].text.strip())
#3==========================================================================================
music_dic = {'rank':rank_li, 'song':song_li, 'artist':art_li}
music_df = pd.DataFrame(music_dic)
music_df.set_index('rank', inplace = True)13일차 웹크롤링 시간 때 긁어왔던 멜론차트를 PANDAS 모듈을 통해 DF로 만드는 작업이다.DF의 index로 순위를 주고, 2개의 Column으로 가수와 노래제목이 나오도록 할것.
% 주석 1번 위
필요한 각 모듈들을 모두 import 한다.우선 Request 모듈의 get 명령어를 통해 차트 홈페이지를 긁어와 보면응답코드가 200이 아닌 406이 뜬다. (13일차에 적었다 보자.)때문에 User Agent라 명명된 부분을 긁어와서 get 명령어의 옵션인 headers에 넣어줘서 res변수에 들여온다.
% 주석 2번 위
주석 2번 부분은 BeautifulSoup 모듈을 사용하는 구간이다.res 라는 변수안에 응답코드가 담겨있을 것이다. (get을 통해 긁어와서 볼 수 있는건 응답코드뿐이다.)
해당 변수를 BS 명령어를 통해 읽어들일 수 있는 html 코드로 불러오며 사용한 Parser는 < html.parser >이다.
참고로 Request.get.text 를 통해 응답코드가 아닌 코드들을 읽을 수 있지만 보기 힘든 값이 많다.
get으로 긁은 값과 BS로 긁은 값 차이.
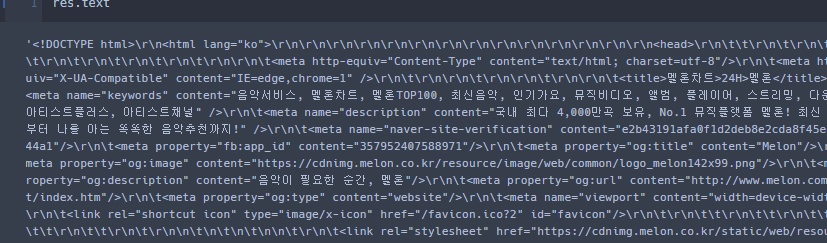
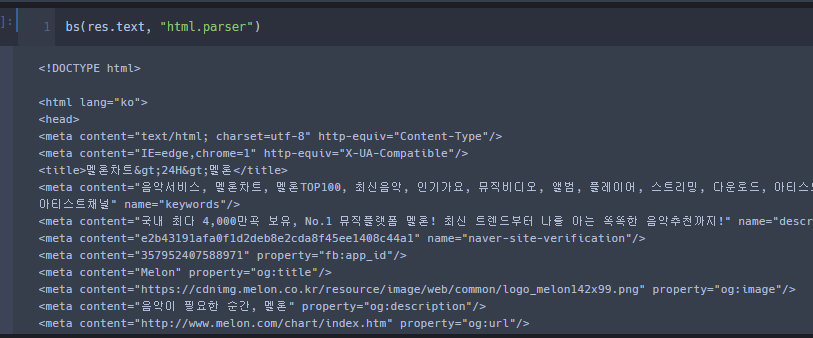
왼쪽이 text, 오른쪽이 BS를 통해 읽어들인 값
그리고 내가 필요한 영화와 평점에 대한 Tag 및 Class(구분자, 선택자)를 찾아 복붙하자.


어 음........ 멜론인데 네이버 영화네.. 무튼 아래에서 똑같은거 진행할거니까;; 무튼오른쪽 마우스의 검색 옵션을 통해 해당 Tag와 Class를 가져온다.
%주석 3번 위
해당 부분은 단순히 리스트에 담기 위함이다.음.. chart_m 이라는 음악을 담고 있는 부분의 경우 Strip 명령어가 아니면 공백이 같이 표기되어 사용해주었다.
%주석 3번 아래
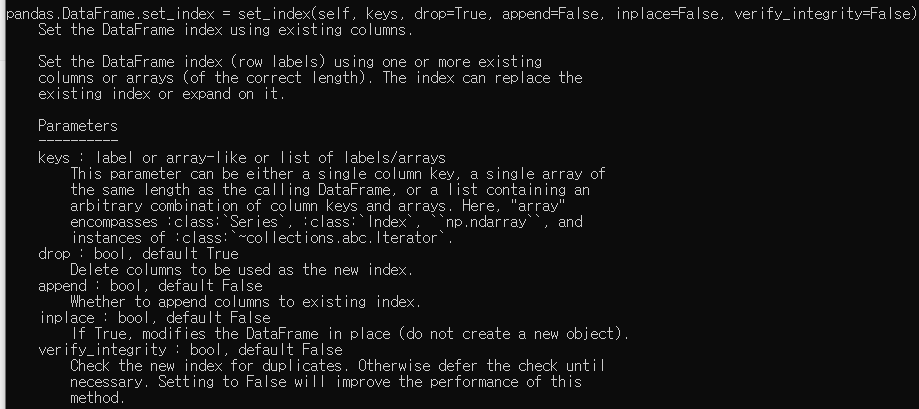
해당부분이 중요하다.우선 music_dic이라는 변수에 딕셔너리 형태로 내가 만든 list를 담아준다. List는 Value로, 열의 이름은 Key값으로그리고 Pandas 모듈을 통해 DF로 만들고 index를 바꿔줄건데set_index 명령어는 DF가 갖고 있는 Column을 인덱스로 만들어 준다.옵션 중 하나인 inplace는 Default 값이 False로, True를 주면 굳이 내가 변수에 담지 않아도 music_df 변수에 그대로 저장이 된다.
set_index에 대한 help() 전문.
그렇게 하면 다음과 같은 결과를 볼 수 있다.

%엑셀파일 저장
music_df.to_csv('melon_song.csv', encoding= "utf-8-sig")위에서 만든 DF를 엑셀 파일로 저장할 수 있다. 정리하면
- 엑셀 저장 명령어는 DataFrameName.to_csv(" 엑셀명.csv", encoding = 옵션)
- encoding할 때 쓰이는건 euc-kr / utf-8 / ""(그냥 공백도된단다...) / utf-8-sig / cp949 등이 있다.
- encoding 안하면 엑셀 파일 한글 깨져나온다.
- 파일은 내가 작업하고 있는 공간 안에 나온다.(파이썬 스크립트 파일 경로 내)
@네이버 영화 차트 DF변환
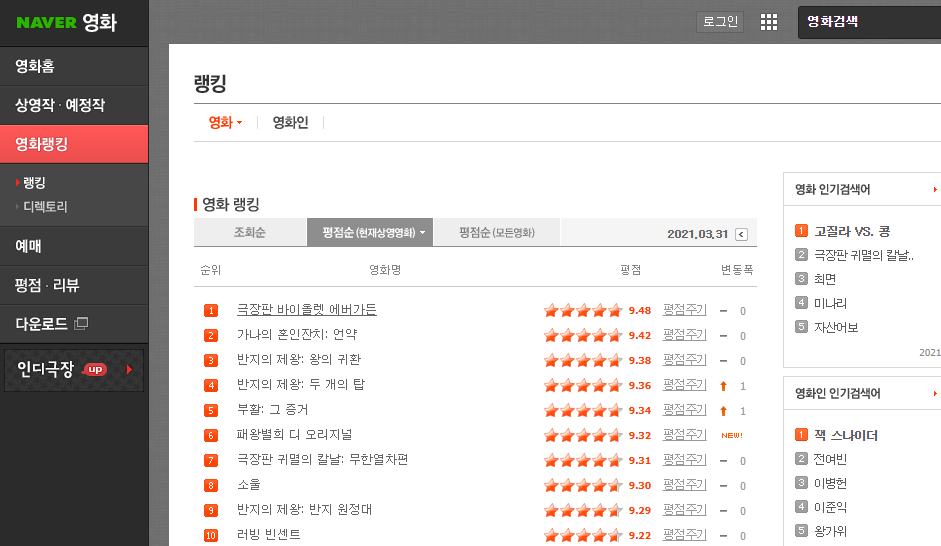
이번에는 네이버의 영화 차트 만들기다. 아래는 코드 전문이다.
#1=========================================================================================
import pandas as pd
import requests as req
from bs4 import BeautifulSoup as bs
mo_req = req.get("https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=cur&date=20210331")
mo_bs = bs(mo_req.text, "html.parser")
mov = mo_bs.select("div.tit5")
pyu = mo_bs.find_all("td", class_ = "point")
#2=========================================================================================
ran_l = []
mov_l = []
pyu_l = []
for i in range(len(mov)):
mov_l.append(mov[i].text.strip())
pyu_l.append(pyu[i].text)
ran_l.append(i+1)
#3=========================================================================================
mov_d={'rank':ran_l, 'movie':mov_l, 'pyungjum':pyu_l}
mov_df = pd.DataFrame(mov_d)
mov_df.set_index('rank', inplace = True)
mov_df.to_csv("naver_movie.csv", encoding = "utf-8-sig")%주석 1번 아래
위에서 실습한 음악차트와 동일하다 다만 다른 점은, 네이버는 UserAgent를 긁어올 필요 없이 그냥 200이 뜬다.
위를 정리하면
- mo_req 변수에 Request.get 명령어를 통해 응답코드 가져오기
- mo_bs 변수에 가져온 응답코드를 text로 변환, html.parser 통해 정리된 문자로 변환
- mov변수에 영화의 Tag및Class 지정 => mov 변수의 경우 Select 명령어 사용 ( select("TAGNAME.CLASSNAME) )
- pyu변수에 평점의 Tag 및 Class 지정, find_all 명령어 이용
%주석 2번 아래
- 3개의 빈 리스트 생성(순위, 영화, 평점)
- for문을 통해 긁어온 각 데이터를 빈 리스트에 append
- Data 확인해서 Strip 이 필요하면 박아 넣을 것. (영화의 경우 양쪽에 공백이 존재함.)
% 주석 3번 아래
- 음악차트와 동일하게 딕셔너리를 생성
- 해당 DF를 만든 딕셔너리를 값으로 넣어 생성
- set_index 명령어로 DF 안의 지정된 Column을 자체적으로 index 지정, inplace Parameter로 바로 저장.
- to_csv 명령어를 통해 엑셀 파일로 저장
그러면 아래와 같은 결과를 볼 수 있다.
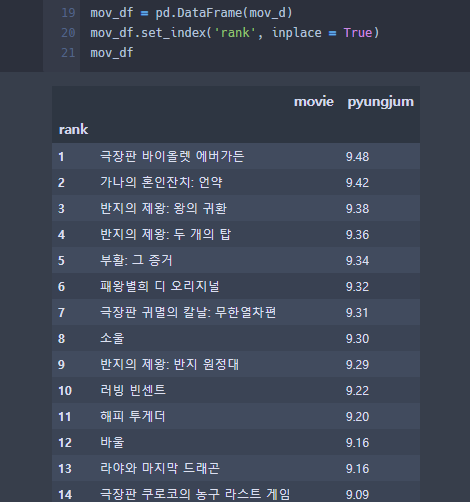
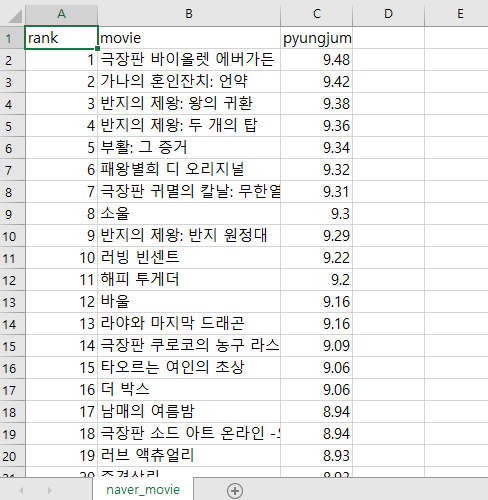
@날짜별 Data 크롤링
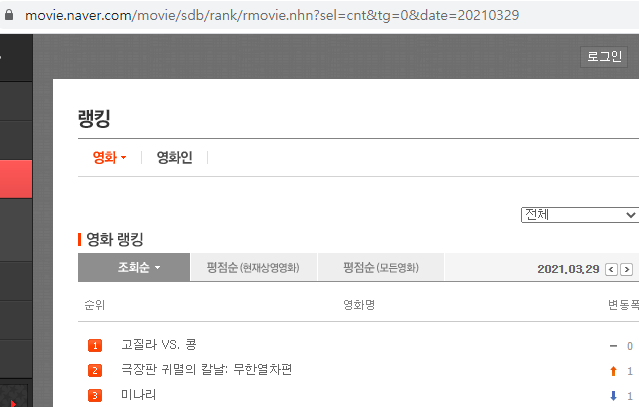
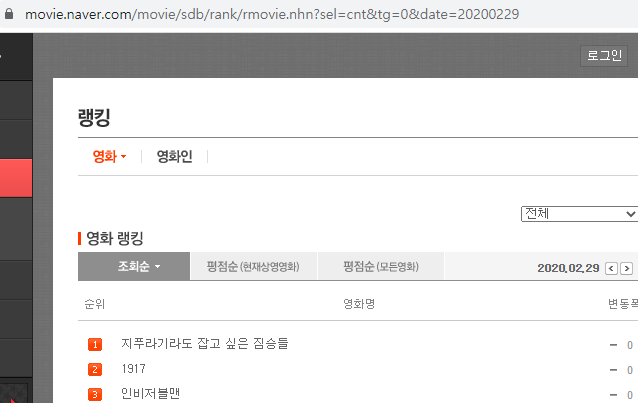
두 사진을 보면 각각 21년 3월 29일 / 20년 2월 29일의 데이터를 나타낸다.
이에 대해 주소를 확인해보면 가장 우측에 날짜가 기입되어있는데 해당 날짜만 바꿔주면 바뀐 날짜의 페이지로 이동함을 볼 수 있다.
때문에 같은 방식으로 주소만 바꿔준다면 위의 예제에서 뽑은 영화 리스트 등을 내가 원하는 날짜만 크롤링할 수 있다.
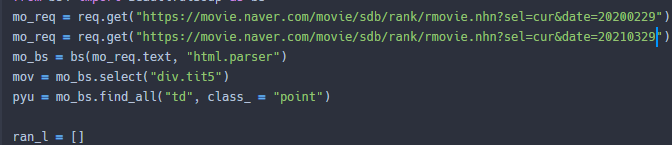
@Pandas - date_range(날짜범위지정)
위의 예제에서 날짜를 바꿔 원하는 날짜의 Data를 수집했다.
그러면 내가 1년치의 데이터를 얻어오고 싶다면 어떻게해야할까?
(당연한 말이지만 for문으로 돌리면 안되겠지 30일 넘어서 40일까찌 쭉쭉 뽑을거다.)
이에 대해 이용할 수 있는 명령어를 Pandas 모듈을 통해 불러들일 수 있다.
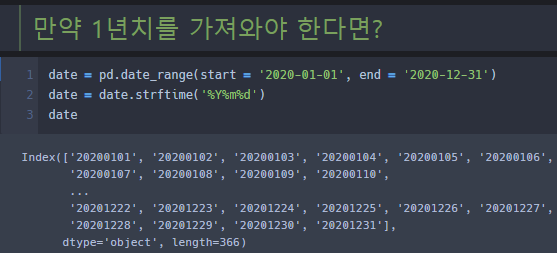
위의 사진을 보면 < date_range(start = 'YYYY-MM-DD', end = 'YYYY-MM-DD') > 명령어로
시작 날짜와 수집할 날짜를 지정하여 해당 Data를 Object 타입으로 얻는다. (솔직히 object 타입 모른다.,)
해당 Data를 for문을 이용한다면 내가 원하는 날짜를 String 타입으로 얻을 수 있다.
%strftime
일단, 내가 주소를 사용하기 위해서는 하이픈(-)을 없애야하는데, 이를 가능하게 만드는 명령어가 < strftime>이다.
사용자체는 사진과 같으며, 대문자냐 소문자냐에 따라 출력되는 형태가 달라진다.
@tqdm.tqdm_notebook - 상태바 Library
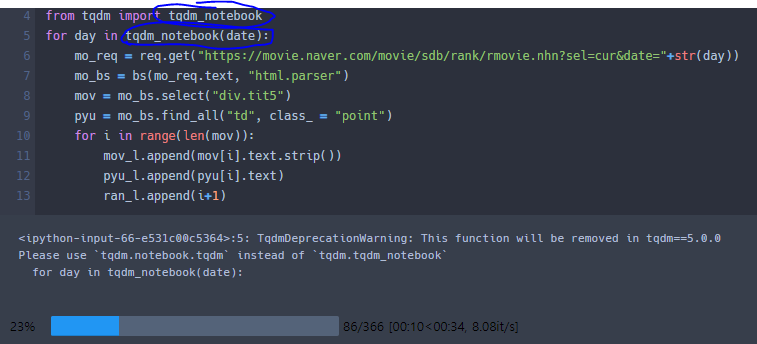
tqdm_notebook 이라는 명령어를 통해 상태바를 표현할 수 있다.
그저 간단한 기능적인 명령어인것 같은데... 일단 이런게 있다라는걸 기록하기 위해 남긴다.
@TOMCAT
이클립스에서 HTML 파일을 실행시키기 위해 Server를 구동해야하는데 이를 위해 Tomcat을 다운받았다.
다운 자체는 아파치의 tomcat 7버전을 다운받았으며 (core란에 64bit 알집파일)
이를 이클립스에서 구동하기 위한 과정을 기록한다.
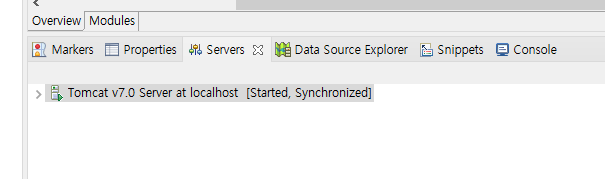
당연히 초기에는 위와 같은 화면은 나오지 않을거다. 이클립스의 하단부에 보면 Server라는 태그가 있는데
(없으면 Window -> Show View로 들어가서 Server 클릭하면 된다.)
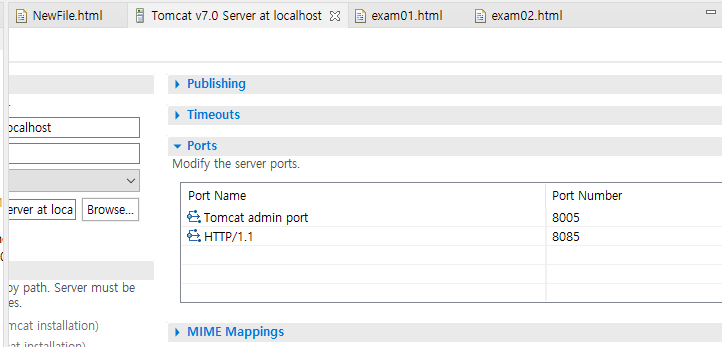
해당 부분에 메세지를 클릭하고 내가 설치한 톰캣7을 선택하면 된다. 뭐 굉장히 간단...
그리고 추가적으로 HTTP port 번호를 8085로 바꿔주셨다. 이에 대한 이유는 모르겠다. 언젠가는 알겠다만...
@HTML - ifram
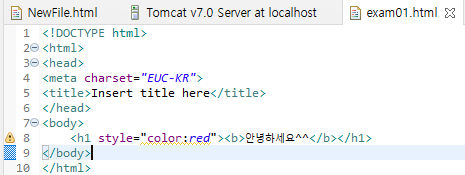
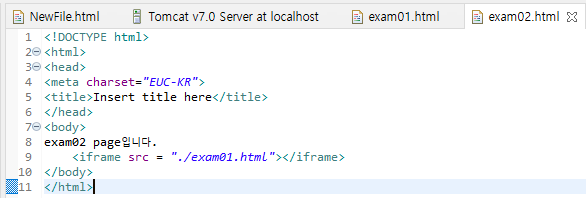
위와 같이 같단한 페이지를 만들었다. exam01이라는 안녕하세요가 출력되는 페이지를 exam02라는 페이지에서
iframe이라는 Tag를 사용해서 같이 붙혀주었다. 02파일에서 01페이지의 위치를 기입하고 exam02.html파일을 실행시키면 아래와 같은 결과를 본다.

뭐 간단하게 구동한거니 별거 없는 페이지이지만... 일단 위에서 안녕하세요라는 문구(exam01 파일)는 클릭하지도 접근할 수도 없다.
즉, iframe 이라는 tag 자체가 해당 페이지를 전광판에 비추듯 보이기만하지 가져오는건 아닌것.
이에 대해서 영화 페이지의 리뷰페이지가 그랬는데,

iframe이 적용된 결과라고 볼 수 있다. 위 페이지에서는 하단의 숫자를 통해 넘어가도 절대 url이 바뀌지 않는다.
말하자면, 한 공간에서 User가 요청한 페이지를 비추기만 할 뿐 이동하지는 않는다는 것.
때문에 내가 저 리뷰들을 크롤링해주려면 iframe을 찾아 해당 페이지로 직접 찾아들어가야 한다.

저렇게 리뷰란을 모두 감싸는 iframe Tag를 찾아 해당 주소(src)를 네이버 영화의 원주소 뒤에 복붙한다.
(https://movie.naver.com/ + "src 주소")
그러면 아래 페이지로 이동한다
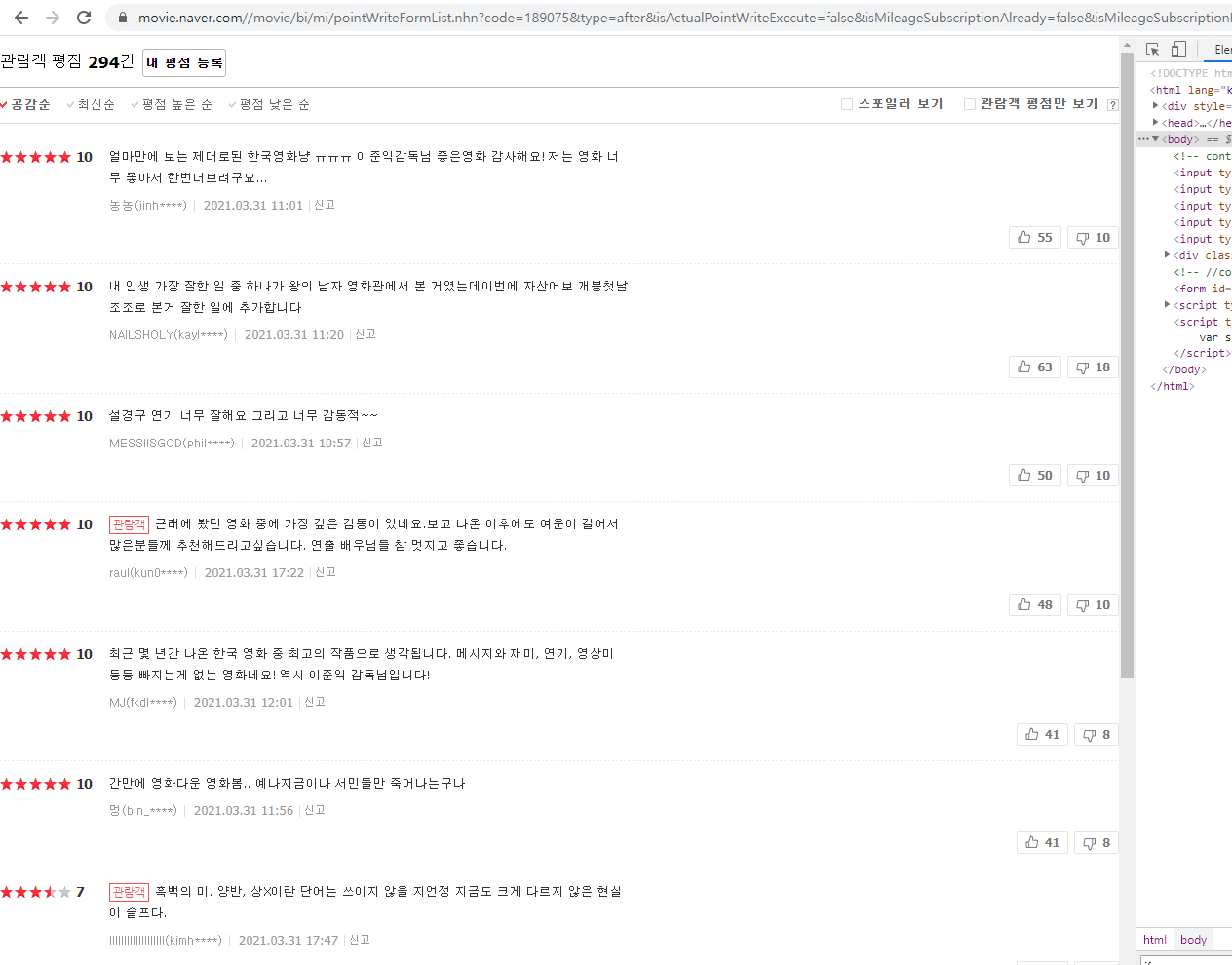
저렇게 하얗게만 변한 화면에서 내가 했던듯 똑같이 tag를 확인하고 id를 확인해서(class가 아니라 id더라)
크롤링을 진행할 수 있다.
import request as req
from bs4 import BeautifulSoup as bs
for j in range(1,30):
rep_req = req.get("https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code=189075&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false&page="+str(j))
rep_bs = bs(rep_req.content, "html.parser")
for i in range(1,10):
reple = rep_bs.find_all("span", id = "_filtered_ment_"+str(i))
print(reple[0].text.strip())
print("\n=====================================================================================================\n")위에서 부터
- rep_req라는 변수에 저 하얀페이지의 주소를 담아 응답코드를 받는다.- rep_bs라는 변수에 BS모듈을 사용해 데이터를 가공한다 (content라는 명령어는 text와 비슷한 기능을 한다고 하는데 차이점은 잘 모르겠다.. 언젠가 알아서 기입하자.)- 그리고 for문을 통해 각 페이지를 확인할건데 리플의 모든 페이지는 29Page고 한 페이지당 리플의 갯수는 9개이다.- 리플을 감싸고 있는 Tag는 span이며 각 리플에는 class대신 id가 지정되어있다. _filtered_ment_ 뒤에 리플 순서가 번호로 매겨져 있는듯 하다.
위의 코드를 구동한다면

이렇게 리플을 가져올 수 있다.
'국비교육기관 > 수업' 카테고리의 다른 글
| 16일차_자바기초_배열이란 / 웹크롤링_Gmarket_이미지크롤링 (0) | 2021.04.05 |
|---|---|
| 15일차_자바기초_for_dowhile / 웹크롤링_Selenium (0) | 2021.04.02 |
| 13일차_자바기초 / 웹크롤링_네이버,멜론 긁어오기 (0) | 2021.03.31 |
| 12일차_자바_기초 / 웹크롤링 (0) | 2021.03.30 |
| 11일차_파이썬_Matplotlib / 오라클_DDL_제약조건 (0) | 2021.03.29 |




댓글