@21.03.31
JAVA
@조건문
파이썬과 기본적으로 원리는 비슷한 조건문쓰
if(조건식){
조건에 해당했을시 시행할 구문
}
과 같은 형태이다. 중괄호로 구별하며 그외 else if / else 를 통해 파이썬과 같은 기능을 한다.
아래는 Scanner와 if문을 같이 사용해본 예제이다.
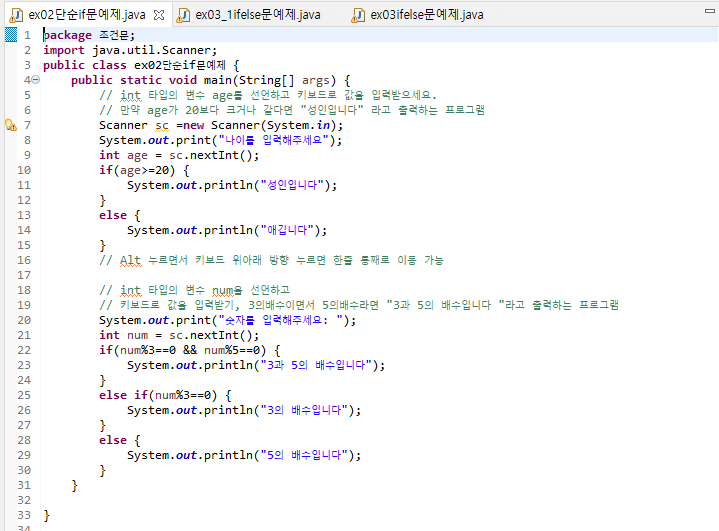
import java.util.Scanner;
public class ex02단순if문예제 {
public static void main(String[] args) {
// int 타입의 변수 num을 선언하고
// 키보드로 값을 입력받기, 3의배수이면서 5의배수라면 "3과 5의 배수입니다 "라고 출력하는 프로그램
System.out.print("숫자를 입력해주세요: ");
int num = sc.nextInt();
if(num%3==0 && num%5==0) {
System.out.println("3과 5의 배수입니다");
}
else if(num%3==0) {
System.out.println("3의 배수입니다");
}
else {
System.out.println("5의 배수입니다");
}
}
}
%Alt + ↕ => 한줄을 내 마음대로 이동할 수 있는 단축키
%조건문예제 - 요금계산
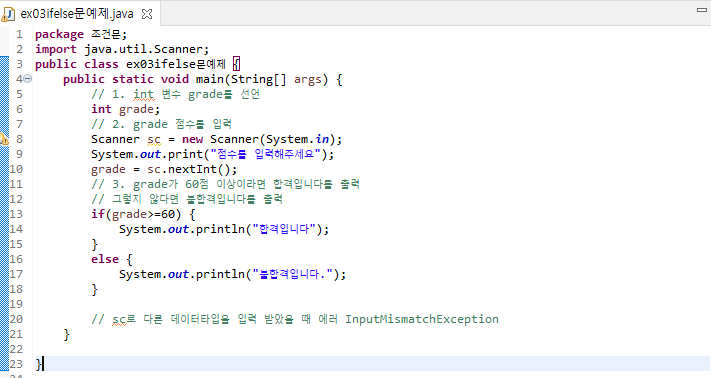
package 조건문;
import java.util.Scanner;
public class ex03_1ifelse문예제 {
public static void main(String[] args) {
// 애버랜드 입장료 계산 프로그램
// 기본료는 5처넌, 인원수에 따라 지불하는 프로그램
int gibon = 5000;
System.out.println("<====애버랜드에 오신 걸 환영합니다!====>");
Scanner sc = new Scanner(System.in);
System.out.println("나이를 말씀해주세요");
int age = sc.nextInt();
System.out.println("인원수를 말씀해주세요");
int inwon = sc.nextInt();
// 단, 미성년자인 경우 50% 할인
// 단2, 나이는 모든 인원 동일
if(age<=19) {
System.out.println("요금은 "+(inwon*gibon*0.5)+"입니다!");
}
else {
System.out.println("요금은 "+(inwon*gibon)+"입니다!");
}
// 삼항연산자로 풀기
System.out.println("요금은 " + (age<=19 ?inwon*gibon/2 :inwon*gibon)+"입니다.");
}
}코드는 주석과 같이 나이는 모든 인원 동일하다는 가정하에, 미성년이면 50%할인 금액으로 금액계산 프로그램이다.
출력은 하나는 if-else문으로, 하나는 삼항연산자로 출력했는데, 이에 대한 결과는

위와 같다. 위의 경우는 .0원이 나왔다.
/2 의 경우는 몫만을 구하기 때문에 당연히 소수점이 없으나 왜 *0.5는 소수점이 나올까?
실수형의 기본형은 Double이다. Double의 크기는 8byte이며, int는 4byte의 크기를 갖고있다.
때문에, 명시적 형변환으로 인해 double로 type 변경이 일어난 것.
@Local Variable - 지역변수
=> 중괄호 안에서(특정구역에서) 선언된 변수는 중괄호 안에서만(특정구역 안에서만) 사용 가능하다.
결국은 무슨 얘기를 하냐면 예로 if-elseif문에서 각 구역마다 result라는 변수에 알파벳별로 담았을 때의 얘기이다. 보면
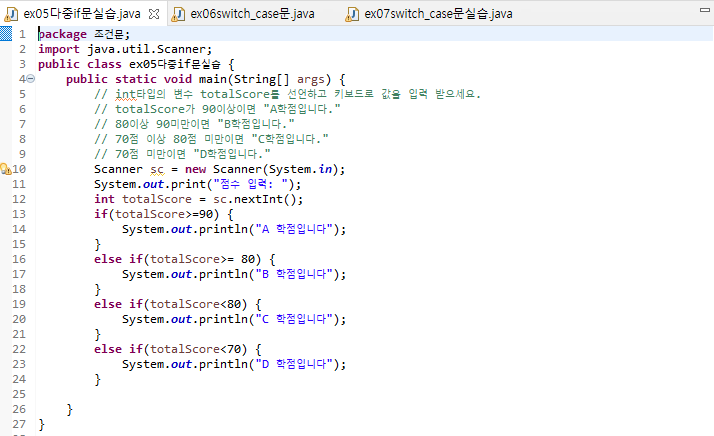
package 조건문;
import java.util.Scanner;
public class ex05다중if문실습 {
public static void main(String[] args) {
// int타입의 변수 totalScore를 선언하고 키보드로 값을 입력 받으세요.
// totalScore가 90이상이면 "A학점입니다."
// 80이상 90미만이면 "B학점입니다."
// 70점 이상 80점 미만이면 "C학점입니다."
// 70점 미만이면 "D학점입니다."
Scanner sc = new Scanner(System.in);
System.out.print("점수 입력: ");
int totalScore = sc.nextInt();
if(totalScore>=90) {
char result = 'A';
}
else if(totalScore>= 80) {
char result = 'B';
}
else if(totalScore<80) {
char result = 'C';
}
else if(totalScore<70) {
char result = 'D';
}
}
}
위와 같은 경우를 말한다. 원레 변수는 중복 선언이 안된다. 즉, 저렇게 데이터 타입까지 적어가면서 여러번 선언하는게 안된다는 소리다. 하지만 위의 경우는 if문의 각 부분에서 선언해준것이기 때문에, 선언이 가능한것뿐. 즉, 지연변수니까
하지만 위와 같은 경우는 if문을 벗어나서는 사용할 수 없다. 안에서 선언된거기 때문에 안에서만 사용가능한것.
그러면 어떻게?
char result=''
int totalScore = sc.nextInt();
if(totalScore>=90) {
result = 'A';
}
else if(totalScore>= 80) {
result = 'B';
}
else if(totalScore<80) {
result = 'C';
}
else if(totalScore<70) {
result = 'D';
}위와 같이 특정구역 밖에서 선언해주고, 안에서는 값만 변경하면 된다.
@Switch - Case, break
기본적인 형태는 다음과 같다.
switch(input) {
case 1:
System.out.println("봄");
case 2:
System.out.println("여름");
case 3:
System.out.println("가을");
case 4:
System.out.println("겨울");
default:
System.out.println("잘못 입력하셨습니다.");
}input이라는 값이 1~4 사이값인 경우 사계절을 출력, 그외에는 잘못입력했다고 출력된다. 다만 위의 결과는

와 같이 싹다 출력해버린다. 때문에 중간에 좀 차단할 구문을 추가가 필요, 이에 대한 구문이 break이다.
break을 걸어주지 않는다면 각 case별로 조건이 만족할때마다 다음 case 구문이 연속실행된다.
Default는 그냥 else..
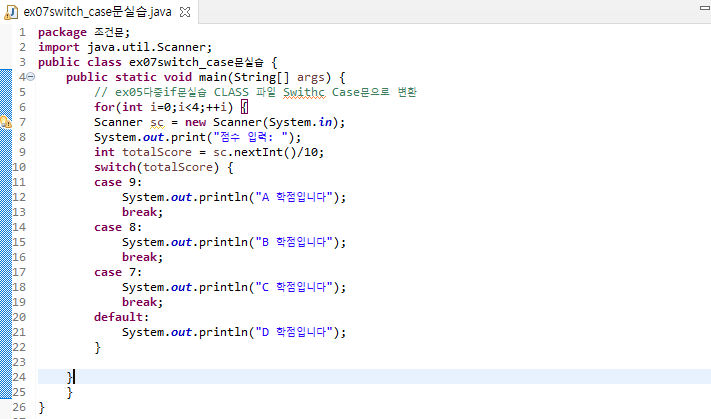
아래는 위의 조건문에서 학점 계산 관련한 예제를 Switch-Case로 바꿨다.
package 조건문;
import java.util.Scanner;
public class ex07switch_case문실습 {
public static void main(String[] args) {
// ex05다중if문실습 CLASS 파일 Swithc Case문으로 변환
Scanner sc = new Scanner(System.in);
System.out.print("점수 입력: ");
int totalScore = sc.nextInt()/10;
switch(totalScore) {
case 9:
System.out.println("A 학점입니다");
break;
case 8:
System.out.println("B 학점입니다");
break;
case 7:
System.out.println("C 학점입니다");
break;
default:
System.out.println("D 학점입니다");
}
}
}
보면 case에는 논리연산자가 아닌 정형화된 값만 들어가야한다. 때문에, 위에서 totalScore란 값을 입력 받음과 동시에 10으로 나눠 몫을 구해줬는데, 각 십의자리 단위마다 학점이 바뀌기 때문에 문제를 풀 수 있는것.
이클립스스캔



================================================
웹크롤링
@Request - get, text
%REQUEST => Page 요청하게 도와주는 모듈
request.get("웹 주소")
를 통해 해당 주소의 정보를 가져올 수 있다.
응답이 200이라 나온다면 잘가져왔다는 뜻.

위에서 res라는 변수에 get을 통해 정보를 읽어 왔는데 이를 text라는 명령어를 통해 읽어 들이면


내가 읽어들인 네이버 사이트의 소스코드(Web)를 읽어들여온다.
@Request - 응답코드406
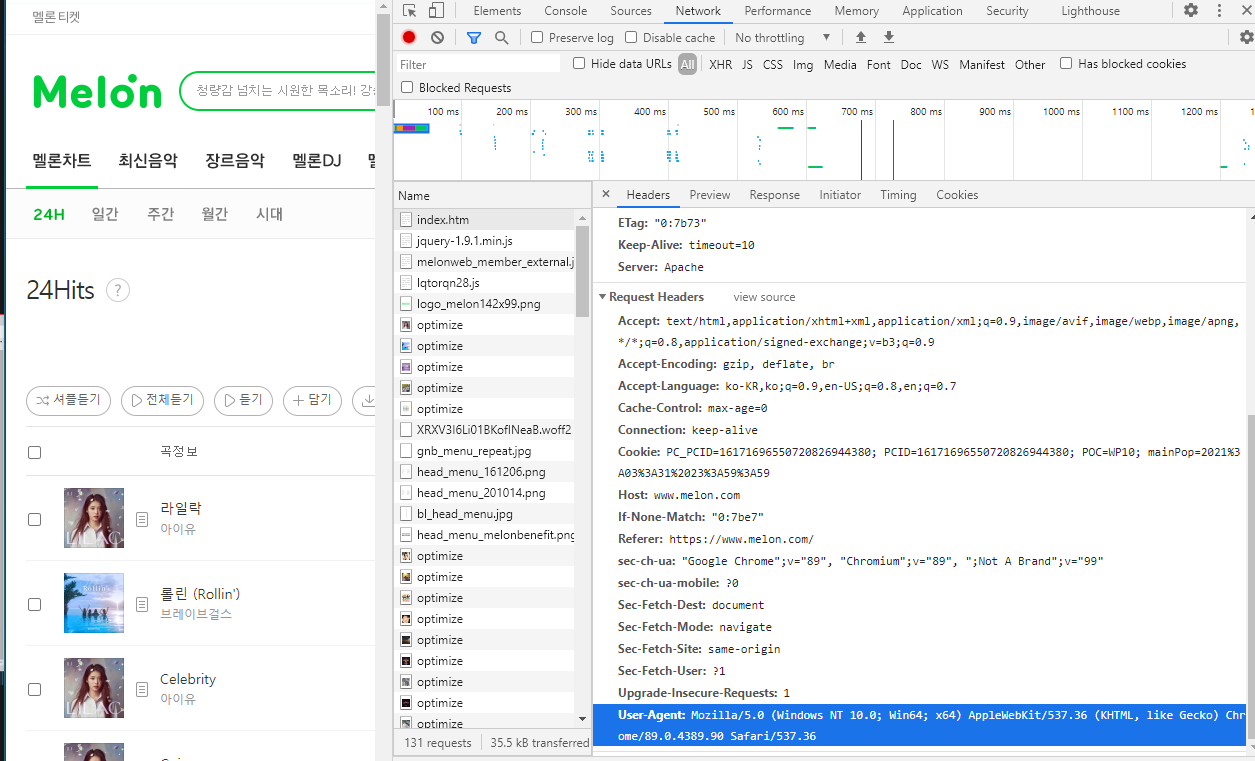
그에 반해 응답코드가 406이라 뜨는 경우 또한 존재하는데. Melon 사이트가 해당 경우이다.

406이라는 응답코드는 사람이 아닌 컴퓨터가 접근했을 때 사이트측에서 접근치 못하도록하여 나타나는 결과라고 한다.
이에 대해서 우리가 크롤링해 올 수 있는 방법에 대한 내용이다.
멜론 사이트에서 F12버튼을 눌러 Elements 부분이 아닌 Network에 사이트 주소의 정보를 볼 수 있는데 여기서,

사이트 주소의 Headers 항목의 제일 아래쪽 보면 User-Agent라는 부분이 있다. 해당 부분으로 인해, 사람이 클릭했을 때가 아닌 컴퓨터가 접근함을 인지하면 접근치 못하도록 막게해준다.
해당 부분을 보면 마치 Dictionary와 같은 형태로 이루어져있다. : 을 구분으로 키와 벨루가 있는데 이를 긁어와서
# 컴퓨터가 아닌 사람으로 속이는 작업# 컴퓨터가 아닌 사람으로 속이는 작업
{"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"}
와 같이 Ditionary의 형태가 되도록 중괄호로 감싸고 문자열로 Key와 Value 별로 만들어준다. 그리고 head라는 변수에 담아

네이버를 긁어오듯 똑같이 한다. 단, 조금 다른점은 내가 담았던 head 라는 변수를 get명령어의 다른 Parameter으로써 headers 라는 값에 대입시킨다.
그러면 위와 같이 긁어올 수 있다.
@BeautifulSoup
- BeautifulSoup이라는 모듈은 bs4라는 모듈안에 존재한다.
from bs4 import BeautifulSoup as bs
# bs(어떤 데이터를 가지고 가공할건지, 어떻게 가공할건지 - 파싱방법)
# lxml이란 설정도 있는데 이는 pip으로 설치해도 안됭
naver = bs(res.text, "html.parser")때문에 from을 이용해 import해준다.
그리고 위를 보면 BeautifulSoup (BS)를 이용해 내가 저장했던 res_text(naver 긁어온 정보)를 안에 넣고
< html.parser >라는 옵션을 넣어줬는데, 이는 내가 긁어올 정보를 가공하게 도와주는 역할을 한다고 한다.
%LXML
위 코드의 주석에도 적었지만 lxml 이란 옵션도 같은 기능을 한다. 하지만, pip으로 install해도 실행이 되지 않더라... 다운 받았는데 다운이 안됐다는 개소리를 뽑아내고... 뭔가 설정을 달리할 필요가 있는듯 하다.

그러면 별 차이는 없어보지만 이처럼 긁어오게 된다.
이를,
result = naver.find_all("a", class_ = "nav")
result[2]위를 보면 BS 안의 명령어 find_all 이란 명령어를 사용했다.
옵션은 순서대로 a태그 안에 감싸여진것 중, Class가 nav인걸 찾아줘 라는 뜻인데.
여기서 Class가 Python 안의 명령어, 용어이기 때문에 뒤에 언더 하이푼을 적어준다. 하면,

이처럼 LIST의 형태로 데이터를 받아온다. (잘보면 대괄호로 싸여있다.)
3번째를 보면 블로그이기 때문에 위서처럼 적으면 블로그만 받아올것.
한데 또 여기서 블로그 라는 말만 받아오고 싶다면 다음과 같이 진행하면 된다.
@NAVER 뉴스 타이틀 가져오기
import request as req
from bs4 import BeautifulSoup as bs
res = req.get("https://search.naver.com/search.naver?where=news&sm=tab
_jum&query=%EC%BD%94%EB%A1%9C%EB%82%98")
naver_n = bs(res.text, "html.parser")
news = naver_n.find_all("a", class_ = "news_tit")
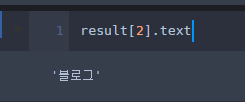
for i in news:
print(i.text)- res라는 변수 안에 request.get 명렁어를 통해 코로나로 검색하고 뉴스를 클릭했을 때의 주소를 긁어온다.
- 그리고 BS를 이용해 naver_n이라는 변수 안에 < html.parser > 옵션을 통해 가공하여 담는다
- news라는 변수 안에 a태그 안에 쌓여있으며 Class가 news_tit인걸 모두 찾는다.
- 그리고 for문을 통해 news 안에 담겨있는 데이터에서 text만 추출하여 뽑아내면 다음과 같은 결과를 얻는다.
%확인할것.
- res 변수를 실행하면 응답코드가 200이라 정상적으로 나오는지?
- naver_n을 통해 가공하여 담았을 때 옵션이 정상적 기능을 하는지? (난 lxml은 안된다...)
- news 변수에 담을 설정을 정확이 넣었는지? ( a Tag 안에 쌓여있는지, 해당 data의 선택자 class 값이 뭐인지)
etc...
@멜론 차트 가수 - 노래 가져오기
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"}
res = req.get("https://www.melon.com/chart/index.htm", headers = head)
cha = bs(res.text, "html.parser")
chart = cha.find_all("span", class_ = "checkEllipsis")
chart_m = cha.find_all("div", class_ = "ellipsis rank01")
for i,j in zip(chart, chart_m):
print(i.text," - ",j.text.strip())우선 코드 전문이다 보면.
- res라는 변수를 request.get 이란 명령어를 통해 긁어오려한다 하지만 반응코드가 406으로 나오지 않기 때문에,
- User Agent라는 값을 갖는 부분을 긁어와 head라는 변수안에 Dictionary 형태로 가져온다.
- cha라는 변수 안에 BS와 < html.parser > 옵션을 통해 해당 페이지의 정보를 긁어온다.
- 그리고 chart라는 변수에 가수, chart_m 변수에 노래제목을 가져올건데, 문제는 a Tag 안에 class가 없다.
- 때문에 그 위 부모 Tag를 조금씩 올라가보면 calss 를 찾을 수 있다.

실행 결과

%STRIP
아래를 보면

노래제목 양 사이드에 줄바꿈이 들어가있다;;
이걸 없애고 싶어서 별의별 행동을 다 했다만... 진짜 간단하고 편한 기능으로 STRIP이 있더라.
뒤에 Strip을 붙히면

보는것과 같이 양 쪽의 공백을 모두 없앨 수 있다.
@BeautifulSoup - Select
Select는 BS의 find_all 과 비슷한 기능을 가졌지만 더 간편한 명령어이다
cha = bs(res.text, "html.parser")
chart_m = cha.select("span.checkEllipsis")
for i in chart_m:
print(i.text)위를 보면 find_all 대신 select를 썼다. find와 다른점은
- class_ 라 구분진 옵션에 값을 대입하지 않는다.- tab 뒤에 온점으로 표시하며 바로 class 값을 붙혀주었다.
음... 그저 더 간편하게 쓰는 명령어
%Class에 대해서
Class 명령어에 대한 내용이다. find_all 에는 해당되지 않으나 Select 관련해서다.

보면 값이 안나온다. 이유는 ellipsis rank02라는 class를 보면 띄어쓰기를 통해 구분지어지는데
이는 곧 Class 값이 2개라는?? 뜻으로 인식해버린다고 한다.
솔직히 자세히는 이해하지 못했지만... 무튼
때문에 띄어쓰기를 온점으로 구분지어주고 실행하면 값을 추출할 수 있다.

'국비교육기관 > 수업' 카테고리의 다른 글
| 15일차_자바기초_for_dowhile / 웹크롤링_Selenium (0) | 2021.04.02 |
|---|---|
| 14일차_자바_WHILE / 웹크롤링_영화랭킹_TOMCAT (0) | 2021.04.01 |
| 12일차_자바_기초 / 웹크롤링 (0) | 2021.03.30 |
| 11일차_파이썬_Matplotlib / 오라클_DDL_제약조건 (0) | 2021.03.29 |
| 10일차_파이썬_Pandas / 오라클_DDL_CREATE_ALTER (0) | 2021.03.26 |




댓글