@21.03.29
@파이썬 - Matplotlib
@Matplotlib - Plot

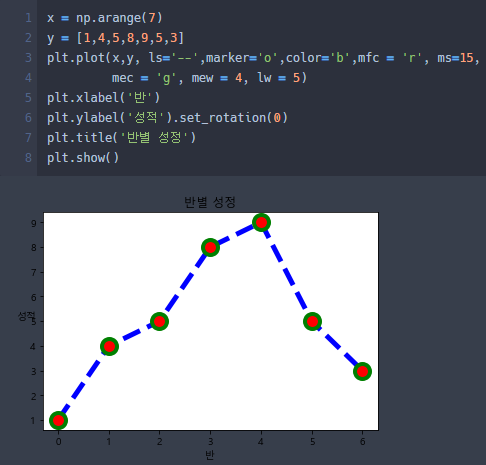
이 사진 한 장으로 요약할 수 있지 않을까??....
그저 데이터 시각화에 특화된 라이브러리.. Matlab에서 plot하는걸 파이썬에 그대로 가져다가 쓰는거지
다루는 법에 있어서는 어렵지 않을거라 생각한다.
그 외에 다른 기능을 하는 명령어들은 아래와 같다.

@Matplotlib - 차트 옵션

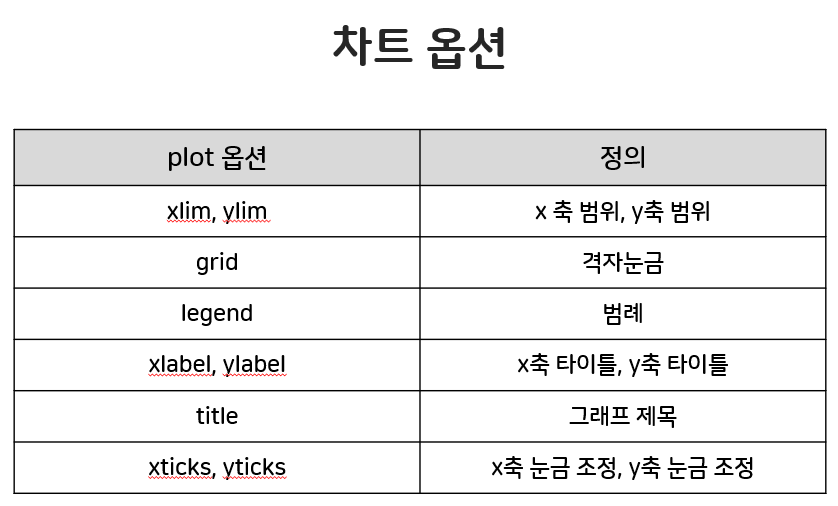
만든 차트에 대한 여러 옵션.
grid는 만든 plot에 격자무늬를 배경으로 삼게 한다.
legend는 각 선에 대한 설명, label은 해당 축에 대한 title설정할 수 있다.
@Matplotlib - 그래프 한글 인코딩

위와 같은 과정에 의해 Matplotlib 모듈의 인코딩 문제를 해결할 수 있다. 이와 같은 과정을 거치지 않는다면 아래와 같이 x,y축의 이름을 한글로 지정했을 때 적용되지 않고, 사각형으로 글자가 보인다. (깨진단 소리.)
@Matplotlib - CSV 파일 활용 예제 (1)
# 해당하는 데이터( Traffic_Accident_2017.csv ) 읽어오기
import pandas as p
data = p.read_csv("Traffic_Accident_2017.csv",encoding = 'euc-kr')
# 요일별로 사고건수 count하기
temp = data['요일'].value_counts()
y = temp[['월','화','수','목','금','토','일']]
x = y.index
plt.bar(x,y)
plt.xlabel('요일')
plt.ylabel('사고건수')
plt.title('요일별 사고건수')
plt.ylim(0,900)
plt.show()위 코드의 주석과 같이 CSV 파일을 PANDAS 모듈을 통해 읽어온 다음, temp라는 변수에 '요일' Column의 Value값을 Value_count 라는 명령어를 통해 count해준다.
그러면 temp라는 변수에 Series 타입으로 각 요일별 수가 있을 것이고, 해당 수가 해당 요일의 사건 수가 된다.
x 값에 y 변수에 담긴 Series의 index 값을 담고, 두 변수를 Plot한다. 그러면 아래와 같은 결과를 볼 수 있다.

@Matplotlib - CSV 파일 활용 예제 (2)
#1. 사고유형 대분류 중 차대차 사고만 뽑아오기
#2. 사상자수, 발생지시도만 필요합니다
temp_car = data[data['사고유형_대분류'] == '차대차']
temp_car2 = temp_car[['사상자수','발생지시도']]
#3. 해당하는 데이터를 발생지시도를 기준으로 합계구하기
car_to_car = temp_car2.groupby('발생지시도').sum()
plt.rcParams["figure.figsize"] = (10,4)
plt.plot(car_to_car)
plt.xlabel('지역')
plt.ylabel('사상자수').set_rotation(0)
plt.title('차vs차 교통사고의 사상자수')
plt.show()(1) 번 예제에서 불러온 data를 바탕으로 진행된다.
첫번째 temp_car라는 변수에 data의 '사고유형_대분류'라는 col이 '차대차'인 것을 걸러내는 불린색인을 진행한다.
해당 값을 data에 다시 집어 넣으면 True인 값이 반환될것이고, 그러면 사고유형이 차대차인 Value 값을 얻을 수 있다.
이에 대한 값은 특정 col만 추출하는게 아닌 행을 뽑는 것이다.
위에서 뽑은 값을 temp_car2라는 변수에 '사상자수', '발생지시도'에 대한 2개의 col만 뽑아내 담아낸다.
%group by
솔직히 오전에 수업집중 안했다... 슬 풀리는것 같은데 궁금하면 찾아보장..
일단 대충 아는것으론 SQL문의 groupby문과 유사하다. 위의 구문대로라면
'발생지시도'를 기준으로 삼아 합계를 구하며, index는 기준이 된 '발생지시도'가 된다.
rcParams는 plot한 그림의 크기를 변경하며, label.set_rotation은 축의 label 글자를 회전시킨다.
이에 대한 결과는 아래와 같다.

파이썬 주피터 노트북







==============================================
오라클 SQL
@DROP-UNUSED
%DROP column
- Data와 저장공간까지 같이 지움
- table의 LOCK 시간이 길다(=table의 동시성이 떨어진다)
%set UNUSED
- table의 상태정보만 변경
- table의 LOCK시간이 짧다(=table의 동시성이 높다)
- data와 공간까지 완전 지우려면 drop unused columns 라는 명령어를 쓴다.
결론은 set unused를 더 선호한다.

사용 예는 위와 같다. DROP의 경우 job_id 라는 Column을 바로 지운반면에, set Unused의 경우 dept 테이블에 나타나지만 않았을 뿐 지워지진 않음을 볼 수 있다.
Drop 이란 명령어 자체를 현업에서는 잘 사용하지 않는다고 한다. 쓰면 바로 Commit 되면서 싹 날라가는데 당연하겠지만...
@지우는 명령어 3가지
%DELETE (DML)
- DATA삭제
- 저장공간남음
- rollback 가능
-> 행단위 삭제
%TRUNCATE(DDL)
- data삭제
- data저장공간삭제, table구조 남음
%DROP(DDL)
- data삭제, table구조삭제
- 걍 다 지움(공간까지)
DDL문은 복구(rollback)불가하다. 단, backup본이 있을시에는 가능
table의 data를 삭제하는 명령어 3가지에 대한 차이점이다. 아래는 이에 대한 수업 내용 중 일부

10. 제약조건포함
@제약조건
무결성을 보장하기 위한 조건 => 조건에 맞는 Data만 저장하기 위한 규칙. => Colum단위 설치할 때 Key라는 형태로 설치를 한다.
이에 대한 5가지
Not NULL: null값을 갖지 않는다. 반드시값이 있어야한다.
UNIQUE: 중복을 허용하지 않는다.
Primary Key: 중복을 허용하지 않는 동시에, NULL값 또한 허용치 않는다.
Foreign Key: 참조키
CHECK: 조건에 맞는걸 만든다.
check를 제외하고는 DB에서 제공하는 조건, check는 사용자가 만듬
@CONSTRAINT - 제약조건 생성
constraint dept_did_pk primary key(did)사용 예는 위와 같다. 그대로 처음부터 해석해보면
CONSTRAINT를 통해 제약조건 선언,
dept_did_pk의 경우는 dept Table에 did라는 Primary Key(PK)를 선언
Primary key를 did라는곳에다 선언하겠다.
라는 의미가 된다. ( Constraint 제약조건이름 제약조건유형(설치할 칼럼이름) )
%제약조건 Level
- Column Level : col을 선언하고서 제약조건과 같이 선언. (col 앞에 위치)
- Table Level : col을 선헌후에 제약조건 별도로 선언(col 뒤에 위치)
이에 대해서는 교재 1권 400페이지쯤?? 에있을것 확인하자.
@FOREIGN KEY 생성
FK의 경우 다른 제약조건과 다르게 '참조키' 이기 때문에, 어떤걸 참조할지를 선언해주어야 한다.

때문에, 다른 제약조건 생성할때와 달리 ' REFERENCES ' 라는 표현을 써서 참조할 Table과 Column을 지정 및 선언한다.
@CHECK
Check의 경우 위에서 언급한것과 같이 사용자의 조건 (아래에서는 연봉이 0보다 많을 것.)에 따른 조건을 생성한다.

@SQL EDITOR 만들기
SQL은 메모장의 파일에 작성하여 커맨더창에서 바로 실행시킬 수 있다. 이에 대한 에디터 파일은
save test.sql와 같은 명령어를 커맨더 창에 입력하고나서, test.sql이라는 파일이

의 경로에 있을 것이다. 해당 파일로 들어가 작업을 수행한 뒤, 저장하고
커맨더 창에서
@test.sql처럼 파일명 앞에 @만 붙혀서 실행해주면, 내가 작업한 sql문이 수행된다. 당연히 에디터 파일이기 때문에 내가 몇줄을 적었든, 몇개의 작업을 수행항려하든 상관없다.
@엑셀 파일 보고, Table 생성하기

위와 같은 Table 정의서에 따라 Table을 만들거다. 우선, 작성한 코드는
create table dept
( deptno number(2),
dname varchar2(14) not null,
loc varchar2(13),
constraint dept_deptno_pk primary key(deptno)
);
create table emp
( empno number(4),
ename varchar2(10) not null,
job varchar2(9) not null,
mgr number(4),
hiredate date,
sal number(7,2) not null,
comm number(7,2),
deptno number(2),
constraint emp_empno_pk primary key(empno),
constraint emp_deptno_fk foreign key(deptno)
references dept(deptno)
);
와 같다. (해당 Table을 생성하기 위해서 위에 언급한 에디터 파일을 활용하였다.)
- 제약조건 NN의 경우는 선언한 Col의 type 뒤에 써준다.- FK의 경우에는 emp Table에 deptno Column을 dept Table의 deptno Column을 참조하여 선언한단 뜻- 작성간에 ' , ' 잘 확인할 것.
@CASCADE & Set Null
%CASCADE
Cascade의 경우 예로 A라는 Table의 R이라는 PK를 B라는 Table의 R이 FK로서 참조하고 있을 때,
ON DELETE CASCADE라는 명령어로 부모 Table인 A와 종속되어있는 자식 Table B까지 한꺼번에 지운다.
=> 종속되어있는 Table까지 싹 다 지운다.
EX)

drop table dept cascade; 명령어는 emp table까지 지운다.drop table dept cascade constraints; 는 emp FK를 삭제한다. 즉, 관계를 의절한다라는 표현과 비슷함.
%Set Null
set null의 경우 해당 colu을 null값으로 바꿔버린다.
11. 뷰 생성
@VIEW - AS SELECT
View와 관련하여 as select문은 전 시간에 배웠던 Table의 AS SELECT문의 사용범과 동일하다.
아래는 View의 As Select문을 이용하여 View를 생성한것이다.

%VIEW와 TABLE의 차이
Table
- 구조를 가지고 있다. => 물리적인 저장공간을 할당 받는다. ( Table의 구조, data 등을 저장)(Table의 구조에 대한것은 Data Dictionary에, Data는 File의 형태로 저장한다.)
View
- 가짜 table or 논리 table이라 불린다.
- 구조가 없다 => 즉, 물리적인 저장공간이 없다.
- Data Dictionary에 View를 생성할 때 썼던 문장(Text)를 저장함.
=> 만일, View를 조회하면 View를 생성할 때 사용한 Text를 재실행한다.
=> 때문에, 마치 Table인것 처럼 보이는것뿐, 아니다.
=> 당연한 얘기지만 이러한 이유로 인해 성능은 좋지는 않다.
@인라인 뷰
간단한 예로 From절에 사용하는 SQ를 말한다.
asdasd
%TOP-N 분석
@Rownum
출력되는 행의 번호를 출력해준다.
sysdata와 비슷한 개념 ( Table에 없는 Column이라도 출력된다.)

단, Rownum이란건 행의 번호를 저장하고 있는게 아닌 출력이 되고나면 번호를 달아준다.
예로

이와 같은 구문은 작동하지 않는다. 왜냐면 해당 where절을 만족하기 전에 col이 출력되지 않았기 때문에 rownum이란 녀석은 아무에게도 행번호를 달아주지 않았기 때문이다.
반대로

위의 경우 처럼 rownum < 4의 경우는 출력이 된다. 한번 예로 들어보면 내가 rownum == 3 인 경우를 출력했다.
그러면 1,2번째의 경우는 3이 아니니까 당연히 제외된다. 근데, 3에 해당되는 경우는 출력되자마자 rownum=1 이라는 값을 부여받게되는것이다.
즉, rownum=n 이라는 조건절에서 rownum은 어떤 경우에도 첫번째로 출력된 행에게 1이라는 값을 부여한다는 것이다.
SQL문제
-> 부서별 평균급여가 많은 3개의 부서의 부서번호와, 연봉을 부를것.
select rownum, department_id, "salary"
from (select department_id, avg(salary) "salary"
from employees
group by department_id
order by avg(salary) desc)
where rownum < 4일단 from 절을 통해 SQ를 만들어(인라인뷰) 평균급여를 뽑아낸 것.
Table에서 뽑아낸게 아닌 View에서 뽑아낸 값이기 때문에 Alias를 통해 값을 호출해야한다.
그리고 상위 3게가 필요하니까 rownum이 4보다 작을때를 where절로 걸어주었다.
12. 기타 데이터베이스 객체
@시퀀스

@시퀀스 생성

Increment 증가값
Start with 첫번째 생성 값 => 120번부터 시작한단 뜻
Maxvalue 최대 생성 => 9999번까지 추출된다는 뜻 (갯수가 아니다.)
Nocache => 갯수?...
Nocycle => Cycle옵션을 주면 9999번까지 가더라도 다시 120번부터 만든다.
==> 만일 PK인데 Cycle을 줘버리면 2번째 도는 120번부터 다 중복되버리기 때문에 에러난다.
아래는 시퀀스를 사용한 예이다. 첫번째 사진 처럼 우선 시퀀스를 생성한다.
300부터 10씩 9999까지 증가하는 시퀀스를 만들었다. (300,310,...,9980,9990)

그리고 departments Table에 만든 시퀀스를 토대로 3개의 행을 insert 해준다.


그러면 위와 같이 300에서 시작하여 10씩 증가한 3개의 행을 볼 수 있다.
@NextVal & CurVal
N이 SQ에서 값을 추출, 해당 추출한 값이 C에 저장된다. C는 해당 저장된 값을 반환한다??...
@인덱스
검색속도 향상을 위한 목적을 갖고 있음
13. 사용자 액세스 제어(DCL)
Data의 User를 관리하는 방법
1. User 생성
2. User에게 권한 부여 및 회수를 통해 User 제어
3. 통제를 위한 특정 상황에서의 삭제
이 3가지로 관리한다. 해당 사항에 대해선 DBA란 그룹이 관리를 함.
GRANT: 권한 부여
REVOKE: 권한 회수
이 정도만 알라구한다.
%DCL 권한그룹
DCL문 (권한 부여&회수)을 사용하기 위해서 해당 권한을 갖고있는 system 계정에 로그인하였다.
내가 평소 들어가던 계정이 아닌 ' system ' 계정 혹은 'sysdba' 와 같은 특정 그룹이 해당 권한을 갖고 있다고 한다.
그냥 알아두장.
전체적으로 많이 어렵다.... 이에 대한건 공부하구 후일차에 추가토록 하자.
'국비교육기관 > 수업' 카테고리의 다른 글
| 13일차_자바기초 / 웹크롤링_네이버,멜론 긁어오기 (0) | 2021.03.31 |
|---|---|
| 12일차_자바_기초 / 웹크롤링 (0) | 2021.03.30 |
| 10일차_파이썬_Pandas / 오라클_DDL_CREATE_ALTER (0) | 2021.03.26 |
| 09일차_파이썬_Pandas / 오라클_INSERT_UPDATE (0) | 2021.03.25 |
| 08일차_파이썬_Numpy_Pandas / 오라클 SQL_서브쿼리 (0) | 2021.03.24 |




댓글