@21.03.26
@Pandas
@apply

apply라는 함수를 통해 특정 함수를 매개변수로 집어 넣고 행,열 단위로 작업을 처리할 수 있다.
@fillna - 결측치 채우기

value_count라는 함수를 사용하여 딕셔너리 안의 values값을 카운트해주었다.
위와 같은 data를 만들었을 때, B의 경우 3과 5가 없기 때문에 NaN이라는 결측치가 나온다.
이에 대해 fillna라는 함수를 사용하여 결측치를 대체할 수 있다.,
(SQL 에서 NVL과 같은 기능 수행)

@cut - 카테고리 만들기
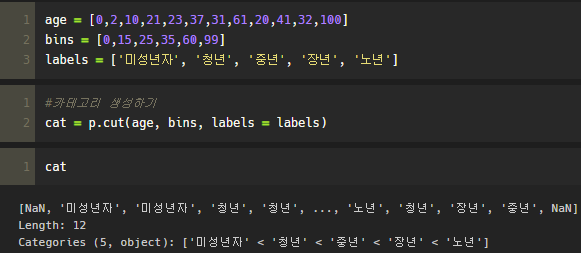
위 사진과 같이 " cut "이란 명령어를 통해 일종의 Categorie를 만들 수 있다.

이에 대한 Catetorie는 그대로의 단어를 사용하여 확인할 수 있다.

위를 보면 " df_age "라는 변수로 DF를 하나 만들고 이에 ' age_cat ' 이라는 Column을 ' cat '변수(카테고리)를 추가하면 해당하는 결과를 볼 수 있다.
@Concat
df1 = p.DataFrame({'A':['A0', 'A1','A2','A3'],
'B':['B0', 'B1','B2','B3'],
'C':['C0', 'C1','C2','C3'],
'D':['D0', 'D1','D2','D3']
}, index = [0,1,2,3])
df2 = p.DataFrame({'A':['A4', 'A5','A6','A7'],
'B':['B4', 'B5','B6','B7'],
'C':['C4', 'C5','C6','C7'],
'D':['D4', 'D5','D6','D7']
})
df3 = p.DataFrame({'A':['A8', 'A9','A10','A11'],
'B':['B8', 'B9','B10','B11'],
'C':['C8', 'C9','C10','C11'],
'D':['D8', 'D9','D10','D11']
})위와 같은 Data를 통해 " concat "이라는 명령어를 통해 결과값을 만들면 아래와 같은 결과를 볼 수 있다.

SQL에서의 JOIN과 같은 기능을 수행한다고 생각하면 된다.


% ignore_index
해당 concat을 통해 얻은 DF의 기존 index 값을 무시한다는 명령어이다.
보면 True 값을 주어 옵션을 실행하였는데, 이를 통해 Default 값은 False로 주어져 기존의 인덱스를 가져옴을 알 수 있다.
% keys
기존에 있던 DF들의 index를 설정한 key값을 통해 통합한 index를 반환한다.
당연하지만 위의 Ignore Index를 True 값을 주었을 때는 해당 명령이 통하지 않을테다.
@Inner Join & Full Join



%INNER JOIN
Inner Join은 내가 JOIN한 그룹이 교집합과 같이 겹치는 부분만을 (결측치가 생기지 않을) 출력한 결과를 말한다.
%OUTER JOIN (Full Join)
Outer Join은 내가 JOIN한 그룹이 결측치가 생기는 부분까지 포함한 모든 부분을 반환한다.
위에서 코딩한 결과에서 보면 알 수 있듯(concat부분), join이란 값의 Default 값은 Outer임을 예측할 수 있다.
@merge
#merge 함수
df5 = p.DataFrame({'key':['K0', 'K1', 'K2', 'K3'],
'A':['A0', 'A1', 'A2', 'A3'],
'B':['B0', 'B1', 'B2', 'B3']
})
df6 = p.DataFrame({'key':['K0', 'K1', 'K2', 'K3'],
'C':['C0', 'C1', 'C2', 'C3'],
'D':['D0', 'D1', 'D2', 'D3']
})
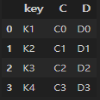
merge 명령어는 위에서 본 Concat과 다르게 한번에 2개의 DF만 JOIN할 수 있다.
위를 보면 " on "에 " key "라는 값을 주었는데. 이건 SQL에서 JOIN을 할 때에 WHERE절을 통해 Primary 키와 Foreign키를 연결하지 않는가? 그것과 같다고 생각하면 된다.
때문에 결과를 보면 다른 Data는 연결될지 언정 " key "라는 Column은 인덱스 처럼 좌측에 표기됨을 볼 수 있다.
@Right Join & Left Join

만일 위와 같은 형태의 DF가 있다고 생각해보자. 전에서 본 Inner와 Outer Join의 개념은 모든 DF의 교집합을 찾았다, 라고 하면 이번은 좀 더 단순한 형태이다. 보면


워어어 씨부레 그림이 너무 크다;;;;
아무튼 순서대로 Right Join과 Left Join인데 보면 RJ의 경우 우측에 있는 C를 기준으로, LJ의 경우 좌측에 있는 A의 기준으로 JOIN이 진행된다. 때문에 이에 대한 코드를 파이썬을 통해 RJ를 예시로 실행해보면


위와 같이 우측의 DF인 " df6 " 을 기준으로 하여 JOIN이 실행된 모습을 볼 수 있다.
%참고(df5 / df6)

@Pandas - CSV파일 사용 실습

%CSV 파일 불러오기

2015~2017이라는 csv 파일을 관서명을 index Column으로 잡고 불러들였다. 형태는 아래와 같다.

%DROP
파이썬의 Pandas 모듈에도 SQL과 같은 Drop이란 명령문이 있는데, 이를 사용해서 2017년 파일에만 있는 " 광주지방경찰청 " 이란 이름을 가진 Data를 삭제 해주었다. 사용 예시는 아래와 같다.
df2017 = df2017.drop('광주지방경찰청')
%총계 구하기
발생건수를 기준으로 각 범죄 건수에 대한 총계를 구하였다. " iLOC "를 이용하여 특정구간에 대한 sum 명령어를 이용하였고, 가로기준(발생건수에 대한 각 범죄들)으로 더하기 때문에 " axis = 1 "을 옵션으로 추가하였다.
보면 모든 행에 대해 불러와야하기 때문에 행은 정하지 않고, 열만 1:6이란 범위(살인~폭력 / 0은 구분)를 iloc에 넣어줌


%총계를 구분된 Column 만들기


구한 " 총계 "라는 값에 대해 s1~s3라는 변수에 담고, 각 Column의 이름을 년도를 붙혀 구별되도록 만든다.
이름을 바꾼 뒤에는 Series의 형태로서 출력하였을 때 우측과 같은 결과를 볼 수 있다.
%연도별 증감율을 구하고 구별되는 Column으로 만들기
# 전년대비 증감율 계산
# 금년(올해) - 작년 / 작년 * 100
t1 = (s2-s1) / s1 * 100
t2 = (s3-s2) / s2 * 100
t1.name = '2015~2016 증감율'
t2.name = '2016~2017 증감율'
#============================================
# 행(가로) 기준 합치기
result_t = p.concat([s1,t1,s2,t2,s3],axis = 1)
result_t범죄의 증감율을 구하는 식은 주석에 달은것과 같으며, 구한 각 Column들을 합치기 위해서 merge가 아닌 concat을 사용하였다. (merge는 한번에 2개 밖에 안되니까..)
Concat을 통해 합칠 때 " axis = 1 "로 주어 가로기준으로 맞추었는데. 만일 그렇게하지 않으면 내가 원하는 표 형태가 아닌 길게 늘어진 영수증 같은 형태의 표를 볼 것이다.
(axis를 세로 기준으로 합쳐버리면 각 관서명을 기준으로 삼은게 아닌 s1 끝나면 같은 관서명 나오고 t1 끝나면 또. 이런 식)
아래는 최종적으로 만든 Data 표이다.

Python_Pandas에 대한 주피터노트북






================================================
오라클 SQL
@병행제어
여러개의 transaction이 동시에 진행된다. 이때 transaction을 보호하기 위한게 병행제어
@교착상태(Deadlock)
%우선 UPDATE에 관하여
만일 2개의 커맨드 창이 있다. 1번 창에서 141번의 봉급을 수정하고, 2번창에서 141번의 봉급을 수정하려 하면 2번창의 경우 대기 상태에 돌입이 된다.
이는 이미 1번 창에서 141번 행에 대해 " LOCK " 이라는 권한이 있기 때문.
=> 이미 실행되고 있는 Transaction에 다른게 개입하려하기 때문에 일어남
무튼, 1번창에서 141번, 2번에서 142번에 대항 봉급을 바꾸고나서~ 2번에서 141번, 1번에서 142번에 대한 봉급을 바꾸려 하면, a번 상황에서 무한대기상태, b번 상황에서 " DeadLock" 이라는 교착상태 메세지가 뜨면서 에러메세지를 볼 수 있을 것이다.
아래의 사진은 위에서 설명한것과 같이 교차되어 업뎃이 진행되었을 때, 2번창에서 142번의 봉급을 바꾸려 하자 1번창에서 뜬 에러 메세지이다.

9. 테이블 생성 및 관리
%DDL(Data Defnition Language - 데이터 정의어)

%객체
- 테이블 ( 기본 저장단위 )
- 뷰 ( 보안 측면에서 사용 - 데이터 엑세스 제어 )
- 시퀀스 ( 숫자 값 생성기 [중복이 되지 않는] ex. 엑셀 숫자 드래그 생각 )
- 인덱스 ( 목차 / data 검색 속도 향상 )
- 동의어 ( employees == emp )
DDL문은 DML문과 다르게 실행하자 마자 바로 COMMIT 된다.
=> DML과 다르게 DDL문은 한문장이 하나의 Transaction이다.
@이름지정규칙

- 반드시 문자로 시작해야 한다.
- 특수 기호는 3번째 명시되어있는것 말고는 사용할 수 없다.
- Departments table과 Employees table에 " department_id "가 공통으로 있듯, 이름이 중복되도 괜찮긴 하다.. 다 만... 같은 table에만 있지 않으면 된다.
@CREATE TABLE
사용 형식
create table dept
(
deptno number(2),
dnmae varchar2(14),
loc varchar2(13)
)CREATE TABLE 문은 위의 코드와 같이 table을 생성할 수 있는 명령어이다.

이렇게 생성한 Table에 INSERT 문을 통해 값을 넣어보자.


그리고 확인을 해보면

이렇게 Table을 생성하고, " COMMIT " 명령어를 통해 Data를 완전히 저장한다.
현재까지 진행한 과정이 " DB구축 " 의 기본적인 단계라고 할 수 있다.
=> 1. CREAT 통해 Table 생성 / 2. INSER를 통해 Data 삽입 / 3. COMMIT 통한 저장.
%왜 LOC Column의 값을 숫자로 넣었는데 오류가 나지 않는가?
제목 그대로 처음 Creat문을 이용해 LOC를 설정할 때에 데이터 타입은 문자였다. 하지만 집어 넣을때 문자가 아닌 숫자를 넣었고 이에 관한 오류 메세지가 없었다.
이는, 오라클에 자연스레 내장된 기능이라고 한다.
숫자도 일종의 " 수를 나타내는 문자 "이며, 오라클은 초기에 Create문에 설정된 Column에 따라 그냥 문자로 인식하고 박아준 것이라고 한다.
@데이터 유형
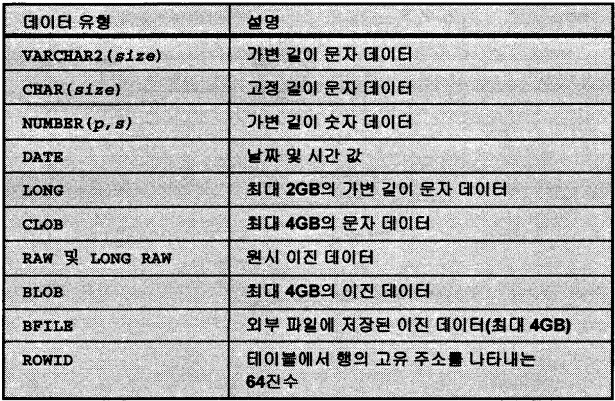
기본적으로 많이 쓰이는 TYPE은 4가지 <VARCHAR / CHAR / NUMBER / DATE >이다
% VarChar & Char
Character의 경우 내가 저장할 공간을 초기 설정한 값에 따라 지정해 놓는다.
=> 즉, 초기에 5개의 공간을 설정했는데 3을 부여하면, 2개의 공간은 논다는 소리
이와 다르게 Variable Character의 경우 데이터의 길이에 따라 공간을 활용하며, 필요없는 공간은 쓰지 않는다.
=> 말 그대로 5개의 공간을 지정, 3개를 사용하면 그에 맞춰 공간이 줄어든다.
이와 관련하여 성능면에서는 Character가 성능이 좋고 Variable의 경우 좀 더 떨어진다.해당 이유는 Dictionary Table이라 불리는 곳에 내가 사용가능한 공간의 Data가 저장이 된다고 한다. VarChar의 경우 당연히 Data가 집어 넣어질때마다 DT의 내용 정보가 변경이 되므로 더 그렇다고 한다. => 이와 연관된 내용은 Window의 " 디스크 조각 모음 " 이란 기능이다. 이해가 덜 됐으니 함 보자.
DB의 확장성을 고려하여 Char의 길이는 < 필요길이 X 20% > 정도가 좋다고 한다.
@CREATE의 SQ - AS SELECT
create table dept90
as select last_name, salary
from employees
where department_id = 90기본적인 사용법은 위와 같이 as select 문을 통한 결과를 바로 Table로 생성한다.


%Create문의 서브쿼리 기능은 SQ결과를 그대로 Table로 인식해버린다.
1. Column 이름 / DataType / 길이를 가져온다.
2. Data도 가져옴.
3. 무결성의 제약조건까지 가져온다. ( 보면 Last_name 부분에 NOT NULL 이라고 명시되어 있다. )
% Creat문과 Alias

Error 메세지를 읽어보면 해당 표현에 대해 alias를 이용하라고 한다. 이에 대한 이유는 Table 생성 규칙에서 특수문자 사용 제한 때문이다.
때문에, 연봉을 표기하고 싶다면 Alias를 통해 Table을 생성하는 과정이 필요하다.
(특수문자가 들어간 연산으로 발생되는 Column을 위해서는)
@INSERT의 SQ
INSERT의 SQ는 CREATE SQ와 비슷하게 결과를 Data로 가져온다. 단, 차이점은 Data의 구조는 가져오지 않는다.
자주 사용하는 방식은 아니라고 한다. 아래는 사용 예제이다.

@ALTER TABLE
(딱히 관계있는 말은 아니다만 현업에서 그렇게 선호하는 문은 아니라고 한다.,)
Alter문은 다음과 같을 때 사용한다. - Data type변경, 길이를 키우거나 줄이거나 (기존 Column 수정) - 새로운 열 추가 - 열을 삭제할 때.
추가 / 수정 / 삭제에는 ADD / MODIFY / DROP 이 사용된다.
%ADD

추가는 위와 같이 간단하게 이뤄진다. 단, Column만을 추가했기 때문에 내용은 당연히 null 값을 갖는다.
추가한 job_id라는 Column에 Data를 삽입하려면 UPDATE문을 사용한다.
=> INSERT는 행 단위로, UPDATE는 열 단위로 작업이 수행되기 때문에 Update가 맞다.
%MODIFY

수정은 위와 같이 간단하게 수행할 수 있다., ( dnmae라는 열의 길이를 30자로 수정하였다. )
단, Table안의 Value값 중 특정 값보다 작은 숫자로 줄이려하면 다음과 같은 결과가 나온다.

위와 같이 무결성에 맞지 않는 결과는 수정되지 않는다.
그 밖에도 이미 NUMBER 타입이 있는데 이를 Char로 바꾸려 한다거나 하는 식 또한 되지 않는다.
'국비교육기관 > 수업' 카테고리의 다른 글
| 12일차_자바_기초 / 웹크롤링 (0) | 2021.03.30 |
|---|---|
| 11일차_파이썬_Matplotlib / 오라클_DDL_제약조건 (0) | 2021.03.29 |
| 09일차_파이썬_Pandas / 오라클_INSERT_UPDATE (0) | 2021.03.25 |
| 08일차_파이썬_Numpy_Pandas / 오라클 SQL_서브쿼리 (0) | 2021.03.24 |
| 07일차_파이썬_Library_Numpy / 오라클 SQL_JOIN (0) | 2021.03.23 |




댓글