@21.03.23
@Module(모듈)
모듈은 곧 Library를 말함. 파이썬에서 사용 가능한 모듈의 확장자 명은 < .py >이다.
필요한 코드를 재사용하기 위해 변수나 함수, 클래스를 모아 놓은 파일
파이썬 강의에서는 < Numpy / Pandas / Matplotlib > 이렇게 3개의 Library를 배우게 된다. 판다를 제외하고는 다 사용해봤지만.. 다 기억안난다.. 쓴지가 얼마나 오래됐는데... 뭐 앞으로 배우면 기억 나게찡23
@Numpy(Numerical Python)
- 빠르고 효율적인 벡터 산술연산을 제공하는 다차원배열 제공 (ndarray 클래스)
- 선형대수, 난수 생성, 푸리에 변환
- 반복문 없이 전체 데이터 배열 연산이 가능한 표준 수학 함수 ( sum,sqrt,mean)
@Numpy.ndarray 클래스
- 동일한 자료형을 가진다.
- 각 값들은 index를 가진다.
- N차원 형태로 구성이 가능하다.
- ndarray를 array라고 표현한다. (표현만 하는게 아니라 실 사용에서도 array로 쓴다.)
- LIST 자료형보다 array를 사용하여 정보를 저장하는게 Memory를 더 적게 잡아먹는다.
- array구조의 데이터는 출력 함수를 통해 출력하면 ' , '가 없이 나온다.
@shape / size / dtype
shape과 size는 각각 배열의 행열 수(row,column)와 배열의 인자 값(요소 갯수)를 반환한다.
dtype의 경우 배열의 type을 반환한다.

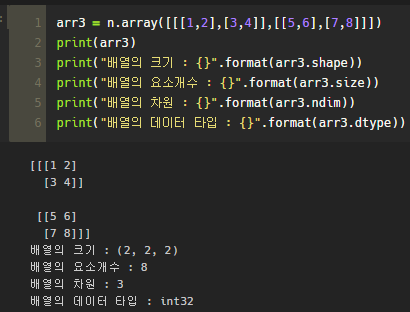
@ndim (Dimension - 차원) / 3차원 배열 만들기
ndim의 경우 배열의 차원 수를 반환한다.

3차원 배열의 경우 음.. 그냥 컴마 좀 늘리고 하면 된다. 간단히 그림을 통해 확인하자
@ numpy. ones / zeros / full
ones, zeros는 의미 그대로이고, full은 내가 원하는 값으로 배열을 생성할 수 있다.
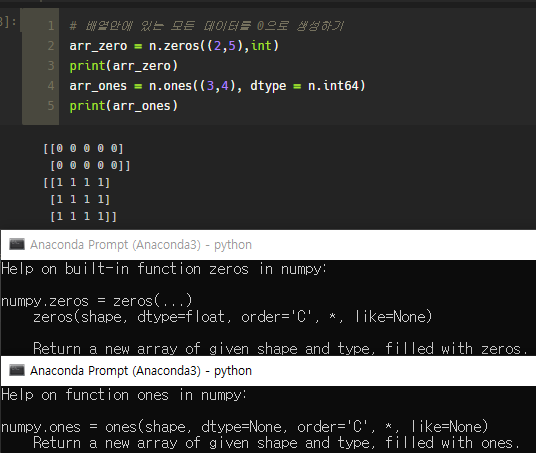

위 처럼 기본 Default 값은 float이다. 때문에 나 같이 'int'라고 지정해줘도 되고, 강의 내용과 같이 'dtype = 'i' or int' 처럼 바꿔도 된다.
@numpy.reshape (배열 재배열)
내가 만든 배열의 크기를 다시 재배열하는 명령어. 내가 갖고 있는 행렬의 요소 갯수를 확인하고(numpy.size) 명령어를 사용할 것. 행과 열에 따른 갯수가 다르면 에러가 난다.

@numpy.arange ( 순차적으로 증가하는 데이터로 배열 만들기)
제목과 마찬가지 for문에 사용하는 range 구문처럼 순차적으로 증가하는 값을 배열에 집어 넣어 생성한다.

@numpy.random.randint ( 난수 생성 및 배열 생성)
numpy Libray안에 있는 하나의 클래스인 random을 통해 난수 생성 및 랜덤 배열을 생성할 수 있다.

@배열의연산

왜 인지 연산이 된다. 하나는 1,3. 하나는 2,3인데 왜??... 심지어 곱셈도 된다. 행렬 규칙을 따르는 것 아닌가??.... 이거에 대해서는 오류인지 그냥되는건지 한번 좀... 해봐야겠다.
%애스터리스크(*)에 관해서
덧셈이든 뭐던간에 되는 이유에 대해서는 좀 더 알아봐야겠지만,... 일단 내적(dot)이 아닌 애스터리스크를 통한 곱셈의 경우는 내가 아는 행렬의 내적이 아닌 "element-wise"라는 걸 통하기 때문에... 일단 행렬의 크기가 같아야 한다.
예로 (1x3) * (2x3)의 값의 경우 (1x3)의 행렬을 (2x3)의 행렬로 확장하여 곱셈이 진행된다. 때문에 값은 나온다.
내가 아는대로면 (2x3) * (3x4)의 값이 나와야 하지만 에러가 나온다. shape이 안맞는다고 한다. 이 또한 내적이 아닌 '애스터리스크'를 통한 곱이기 때문에 행렬의 크기가 같아야 한다고 한다.그 가장 대표적인 이론은
애스터리스크를 통한 행렬의 곱셈은 교환법칙이 성립한다.

@numpy.loadtxt - 외부파일(.txt 파일) 불러오기

numpy Library를 통해 txt파일을 불러오는 명령어이다. 불러올때에 "delimiter"라는 요소를 통해 구분자를 지어 array 형태로 데이터를 저장할 수 있다.

위의 그림과 같이 특정 txt 파일을 불러오고, 이를 array 형태로 받아 데이터를 활용 가능하다.
아래는 파이썬_numpy 관련 주피터 노트북이다.





오라클_SQL
4. 여러 테이블의 데이터 표시
@JOIN
여러 개의 Table에서 데이터를 뽑아내는 과정
조인 조건 1
1. (n-1)개에 해당되는 조인조건을 where절에 반드시 명시
여기서 (n-1)개는 조인 table의 개수를 말한다. -> 조인조건이 생략되거나 잘못작성 시 Cartesian Product라 한다.

만일 where절에 조건을 명시하지 않는다면, 오라클은 그냥 싹다 뽑는다고 한다. 일적인 예로

위의 결과는 각 table에서 값을 뽑아낸 결과인데, 원래 각각 27개의행, 107개의행인걸 2개 곱한만큼 싹다 생성시킨것.
때문에 아래와 같이 특정 조건을 걸어주어야 한다.

좀 더 쉽게 설명하면 3개의 table을 참조하면 2개, 2개의 table을 참조하면 1개의 JOIN을 걸어줘야 함
@table Alias하기

위와 같이 Blank를 통해 table 명을 각각 알파벳 한글자로 Alias하였다.
여기서 보면 last_name이나 department_name은 각각 e와 d table의 고유 키이지만따로 호출을 해주었다. 해당 이유는 오라클의 파싱 과정에서 처리 속도를 위한 조치이다.
@오라클 조인 - 등가조인(EQ JOIN)
등가조인이란 같은 data가 존재할 시 Primary Key = Foreign Key와 같은 형태의 조건을 걸어주는 조인 방법이다.

그리고 이에 더해 일반적인 조건이 추가된다면 AND 구문을 통해 조건식을 추가하여 준다.

위와 같이 봉급이 5000 이상인 사원의 이름과 부서 이름을 호출하는 SQL문을 작성할 때에는 조인에 따른 where절을 넣어주고 일반적 추가 조건인 봉급관련 조건을 AND를 통해 넣어준다.
@오라클 조인 - (+) (Outer 연산자) 조인


위의 그림과 같이 Outer 연산자를 사용하면, 데이터 값이 null이더라도 부족한 대로 추가시켜 나타내는 녀석이다.
@비등가 조인( None eq JOIN)
@오라클 조인 - 자체조인
%사원의 번호, 이름, 매니저 번호와 해당 사원을 관리하는 매니저의 이름을 출력

self 조인(자체조인)이란건 결국 같은 table을 다른 이름으로 다수번 불러서 구별하여 걸러내는 JOIN을 말한다.
위의 사진을 보면 결국 manager도 사원이다. 때문에 사원을 관리하는 manager 번호는 e table에서 꺼내지만 해당 사원을 관리하는 manager 이름을 호출하기 위해 결국 manager 번호가 employees번호와 일치하는 이름을 manager 이름으로 호출해야하기 때문에 위와 같은 구문을 사용하는 것.
@SQL문제
15. 모든 사원들의 이름, 부서 이름 및 부서 번호를 출력하시오

부서 table과 사원 table을 보면 부서 번호는 겹치고, 부서이름은 부서 table, 사원 이름은 사원 table에 해당한다.때문에 겹치는 부서번호에 대하여 조인을 가해주기 위해 where절을 통해서 걸러낸다.
16. 커미션을 받는 모든 사람들의 이름, 부서명, 지역ID 및 도시 명(locations table)을 출력하시오

일단, 커미션을 받기 때문에 일반적 조건으로 커미션을 받는 사람을 설정.
사원 table과 부서 table의 부서 번호가 겹치기 때문에 이에 대해서 JOIN
부서 table의 지역번호와 지역 table의 지역번호가 겹치기 때문에 이에 대해서 조인.
위의 2가지 조건으로 JOIN을 설정하고 일반 조건을 추가하면 위와 같은 결과를 볼 수 있다.
17. 자신의 매니저보다 먼저 고용된 사원들의 이름 및 고용일을 출력하시오.

일단 해당 문제는 사원과 매니저의 관계를 출력하는 문제이므로 자체조인(Self)이다.
두개의 사원 table을 각각 사원과 매니저용으로 하나씩 참조한다.
manager도 결국은 사원. 하지만 나는 매니저용으로 뽑았으니까 이에 대한 조인을 위해 사원table의 매니저 번호와 매니저table의 사원 번호가 같다고 조건을 걸어준다.
고용일은 당연히 큰 값이 더 늦게 고용된 것. 때문에, 매니저의 고용일이 크다 라고 조건식을 걸어준다.
5. 그룹 함수를 사용한 데이터 집계
@AVG(AVERAGE - 평균) / SUM(합계)
말 그대로 각각 평균과 합계를 구하는 구문이다. 당연하지만 숫자에 대해서만 적용되며 문자인 값(ex - 날짜, 문자)는 사용되지 않는다.

AVG와 SUM은 null값을 무시하고 계산한다. 때문에, 정확한 평균을 원한다면 NVL 함수를 통해 NULL 값을 대체해줘야 한다.
@MIN(최솟값) / MAX(최댓값)
이 역시 최소, 최대값을 구하게 해주는 함수이다. 숫자와 문자 모든 형태에 대해 사용가능하다. 날짜든 문자든 이에 대한 값은 "아스키 코드값"으로 받아들이기 때문.
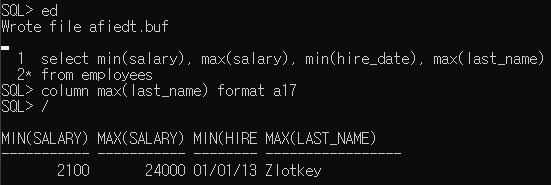
@COUNT(갯수 세주는 함수)
Table의 행 갯수를 반환한다.

위 그림은 50번 부서에 근무하는 사원의 수를 뜻한다고 말할 수 있겠다.
AVG나 SUM, MIN이나 MAX와 다르게 COUNT 함수는 행 단위로 입력을 받는다. 예로,

위 그림과 같은 구문을 작성하면 이는, 80번 부서에 근무하는 사원 중 보너스를 받는 사원의 수를 나타낸다.
@GROUP BY
내가 원하는 형태로 column을 그룹화 시켜주는 명령어. 예로,
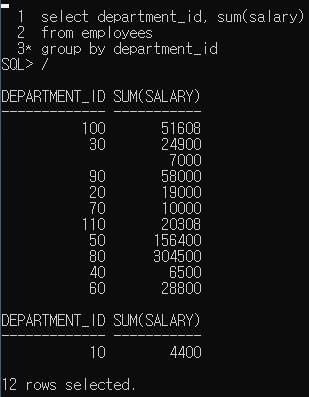
위의 그림과 같이 < department_id >를 그룹화 시켜주면, 부서번호 별로 그룹화가 되어 각 그룹별 Salary의 합계를 나타내는 것. 또 다른 예로

위와 같이 구문을 작성하면 Multiple 그룹화가 가능하다. 부서번호 기준으로 먼저 그룹화를 하고 각 그룹별에 대한 직업번호 기준 그룹핑을 한번 더 하는 것.
GROUPBY 절의 경우 "항상" WHERE절과 ORDERBY절 사이에 존재한다.
@HAVING(그룹에 대한 조건절)
WHERE절의 경우 행에 대한 조건절이며, 먼저 실행된다. 이와 다르게 HAVING절의 경우 그룹에 대한 조건절이며 구문의 나중에 실행이 된다.
단, HAVING절의 경우 WHERE절에 비교하여 성능이 많이 떨어진다.
사용함에 있어 GROUPBY절 전에 쓰여도 상관은 없지만 가독성 측면에서 후에 쓰는게 좋다.
@SQL 문제
18. 회사 전체의 최대 급여, 최소 급여, 급여 총 합 및 평균 급여를 출력하시오

그냥 간단하게 4개의 함수를 이용하는 문제
19. 각 직업별 최대급여, 최소급여, 급여 총 합 및 평균 급여를 출력하시오. 단, 최대 급여는 MAX, 최소 급여는 MIN, 급여 총 합은 SUM 및 평균 급여는 AVG로 출력하고, 직업을 오름차순으로 정렬하시오.

그냥 각 직업별 급여에 대한 4가지 값을 물어보는 것. 여기서 Alias하는 것 말고는 특이점은 없다.
20. 동일한 직업을 가진 사원들의 총 수를 출력하시오.
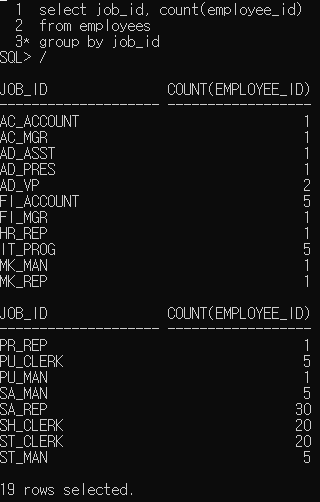
해당 문제는 잘읽을것. 동일한 직업을 가진 사원의 수. 즉, 각 직업별 사원의 수를 출력하는것.
처음에는 COUNT안에 job_id를 집어 넣었는데, 그러면 당연한 말이지만 직업의 수가 나오는 거지 해당 직업의 사원의 수는 나오지 않는다.
'국비교육기관 > 수업' 카테고리의 다른 글
| 09일차_파이썬_Pandas / 오라클_INSERT_UPDATE (0) | 2021.03.25 |
|---|---|
| 08일차_파이썬_Numpy_Pandas / 오라클 SQL_서브쿼리 (0) | 2021.03.24 |
| 06일차_파이썬_함수 / 오라클 SQL_ORDERBY_논리조건 (0) | 2021.03.22 |
| 05일차_파이썬기초_딕셔너리 / SQL plus_SELECT_WHERE (0) | 2021.03.19 |
| 04일차_파이썬기초_조건문 / SQL plus (0) | 2021.03.18 |




댓글