@21.04.06
JAVA
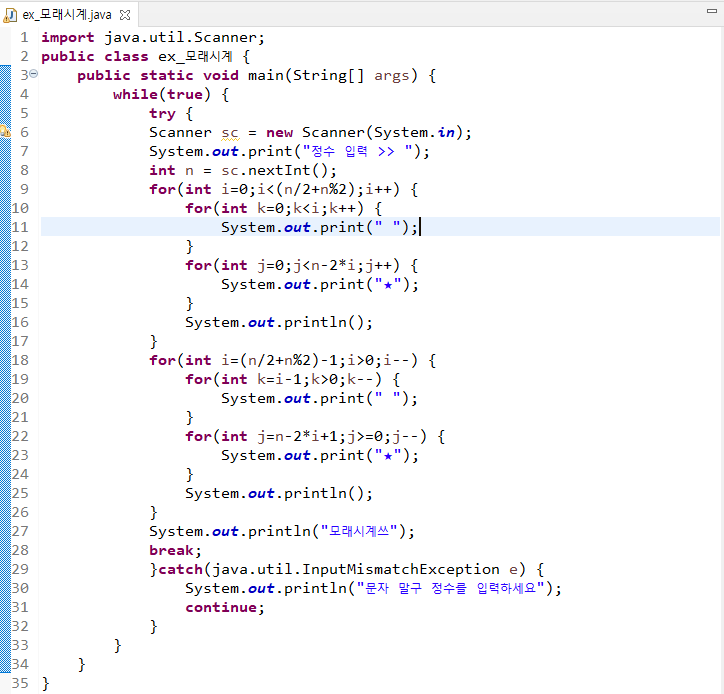
@이중 for문 예제 - 모래시계
import java.util.Scanner;
public class ex_모래시계 {
public static void main(String[] args) {
while(true) {
try {
Scanner sc = new Scanner(System.in);
System.out.print("정수 입력 >> ");
int n = sc.nextInt();
for(int i=0;i<(n/2+n%2);i++) {
for(int k=0;k<i;k++) {
System.out.print(" ");}
for(int j=0;j<n-2*i;j++) {
System.out.print("★");}
System.out.println();}
//=========================================================
for(int i=(n/2+n%2)-1;i>0;i--) {
for(int k=i-1;k>0;k--) {
System.out.print(" ");}
for(int j=n-2*i+1;j>=0;j--) {
System.out.print("★");}
System.out.println();}
System.out.println("모래시계쓰");
break;
}catch(java.util.InputMismatchException e) {
System.out.println("문자 말구 정수를 입력하세요");
continue;}}}}이중 for문.. 결국 그냥 다중 for문이다. 자바는 또 독특하게(내입장에서...) for문 안에서 값을 변경하면 또 적용이되니까.
이런것들을 이용하면 좀 더 효율 적인 코딩을 할 수 있지 않을까??..
무튼 위 예제에 대한것.
- Scanner를 통해 정수를 입력 받는다.
- try-catech 문을 통해 정수가 아닌 문자를 입력한다면(float형태까지) 다시 반복토록 만들었다.
- 짝수개는 2개, 홀수개는 1개로 가운데 별이 표시된다.
- 하나의 모래시계를 만들면 구문은 종료된다.
%구문에 대해
- 주석 기준 위는 역삼각형을 만들며, 아래는 그냥 삼각형을 만든다.- 짝수 기준 해당 갯수에서 1만큼 뺀 갯수의 행이 나와야하고, 홀수는 해당 값만큼의 행 수가 나와야 한다.- 위와 같은 조건을 위해 총 반복횟수는 ( n/2+n%2 )와 같이 각각 주었다. => 홀수던 짝수던 2로 나눈 몫과 나머지 더하면 값이 똑같다. 이걸 이용하여 모두 홀수개의 행으로 시계를 표현- 각 구문을 이루는 구조는 똑같은데 핵심은, 아랫부분은 윗부분 값들을 역으로 대입하면 된다는 것.
%오늘 수업.
금일 수업은 모두 이중for문에 대한 내용이였다. 별찍기 예제만 풀다 끝났는데... 음... 그랬다. 난 놀지 아나썽...
이클립스스캔




================================================
웹크롤링 Test
문제를 풀면서 사용한 Library의 경우 맨 윗줄에 설정해주고 다시 import하진 않았다.
from selenium import webdriver as wb
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup as bs문제1. 자동제어를 통해 네이버 홈페이지에 접속하고 ‘크롤링’를 입력하여 검색하는 수집시스템을 구축하시오.

해설
driver = wb.Chrome()
url = "https://www.naver.com/"
driver.get(url)
input_search = driver.find_element_by_id('query')
input_search.send_keys('크롤링')
btn_search = driver.find_element_by_id('search_btn')
btn_search.click()"크롤링" 이란 단어를 검색하기 위한 방법으로, url이라는 변수에 Naver의 주소를 저장, 네이버의 검색창에 해당하는 id 주소를 WebDriver 모듈을 통해 불러온다

위 사진을 보면 검색창에 해당하는 input Tag의 ID가 query임을 알 수 있다. 때문에,
find_element_by_id 명령어를 통해 ID가 해당하는 부분을 input_search 변수에 저장하여 '크롤링' 이란 Data를 send_keys 명령어를 통해 보낸다.
그리고 검색하는 부분에 있어서는 클릭하는 방법을 썼는데, 이를 위해서 검색창의 정보를 불러들인것 처럼

Button Tag에 해당하는 부분의 정보를 가져온다. ID가 search_btn이므로 find_element_by_id 명령어를 통해 해당 부분의 정보를 불러오고 click( ) 이란 명령어를 통해 작업을 수행한다.
문제2. 자동제어를 통해 G마켓 홈페이지 접속, 조건에 따라 만들기
- G마켓 Best 1~20 순위까지 수집하는 프로그램
- 수집 데이터를 DataFrame으로

해설
from tqdm import tqdm_notebook as tq
driver = wb.Chrome()
url = "http://corners.gmarket.co.kr/Bestsellers"
driver.get(url)
titleList=[]
priceList=[]
categoryList = []
for i in tq(range(1,21)):
number = "no" + str(i)
try:
# 만약에 True이면
first = driver.find_element_by_css_selector("p#"+number+"+div")
first.click()
except:
# 아니고 False이면
first = driver.find_element_by_css_selector("p#"+number+"+span+div")
first.click()
# 상품의 이름, 가격, 카테고리 가져오기
name = driver.find_element_by_css_selector("h1.itemtit").text
price = driver.find_element_by_css_selector("strong.price_real").text
category = driver.find_element_by_css_selector("div.location-navi>ul>li:nth-child(2)>a").text
titleList.append(name)
priceList.append(price)
categoryList.append(category)
print("상품명 >> " + name)
print("가격 >> " + price)
print("카테고리 >> " + category)
# 상품의 뒤로가기
driver.back()전체적으로는 url을 받아 각 상품을 클릭하고, 원하는 정보들을 List에 담는 구문이다. 조금씩 뜯어보면
- 예외처리 구문은 각 상품에 붙은 BIG 택 모양 스티커인 경우를 상정하였다. 해당 부분은 span tag가 하나 더있다.


- 위 그림처럼 big 이란 사진이 붙어있으면 p Tag 아래 span Tag가 하나 더 존재하게 된다.
- 그리고 각 부분별 내가 원하는 정보에 대한 Tag와 Class 명 등을 가져와서 각 변수에 담아 List에 추가한다.
- 각 부분에 대한 Tag or Class or ID 명을 잘모를 때는 Copy Selector 메뉴를 사용하였다.

%DataFrame 만들기
import pandas as p
dic={'name':titleList,'price':priceList,'category':categoryList}
gmarket = p.DataFrame(dic, index=range(1,21))각 변수에 내가 원하는 3개의 정보를 각각 LIST에 담았을 것. dic 이란 변수에 각 Data를 Dictionary 형태로 담아서 Pandas 모듈의 DataFrame을 통해 표로 만들어준다. 그리고 인덱스는 1위~20위 이기 때문에 range를 통해 직접 만들어주었다.
그리고 이에 대한 결과는 다음과 같다.

문제3. 멜론차트에서 1~100위까지 정보를 수집하는 프로그램 작성하기.
- 수집할 정보는 곡정보에 있는 곡명과 가수명이다.
- Pandas의 DataFrame형태로 '순위'를 기준으로 결과를 출력하여야 한다.
- CSV파일로 한글이 깨지지 않게 저장할 수 있는 코드를 작성하여야 한다.
# 순위는 생성해야 한다.
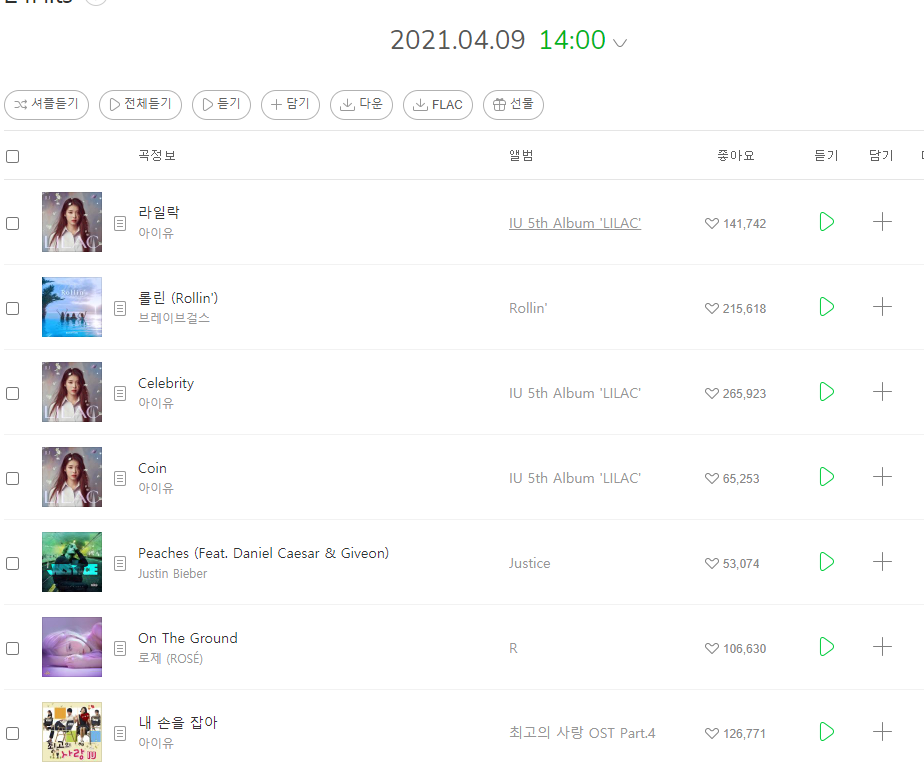
해설
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"}
res = req.get("https://www.melon.com/chart/index.htm", headers = head)
cha = bs(res.text, "html.parser")
chart = cha.find_all("span", class_ = "checkEllipsis")
chart_m = cha.find_all("div", class_ = "ellipsis rank01")
chart_list=[]
chart_m_list=[]
for i,j in zip(chart, chart_m):
chart_list.append(i.text)
chart_m_list.append(j.text.strip())우선 멜론 사이트의 경우 request 모듈을 통해 응답코드를 가져오면 200이 아닌 406이 뜬다. 13일차에서 실습했던 데로 멜록측에서 접근을 막아 놓았기 때문에, User-Agent 라는 부분을 headers 라는 옵션에 대입하여 크롤링을 진행한다. 뜯어보면
- 대량의 Data를 크롤링해오는 것이기 때문에, BeatifulSoup 모듈을 통해 페이지를 가공해준다.
- chart라는 변수에 가수이름을 chart_m이라는 변수에 음악 제목의 정보를 담아온다.
- 각 정보를 빈 List에 반복문을 적용하여 저장한다.
dic = {'rank':list(range(1,101)),'artist':chart_list,'music':chart_m_list}
music_df = p.DataFrame(dic).set_index('rank')
#CSV파일 저장
music_df.to_csv("melon_chart.csv", encoding='utf-8-sig')위에서 저장한 각 List에 대한 값을 dic이란 변수에 집어 넣어 Dictionary 형태로 만들고, DF로 만들어준다.
뭐... 엑셀로 저장하는거야 그냥 하면 되니까 많이 해봤지 않은가. 혹여라도 모르겠다면 찾아보자. 이정도는...
문제3. 자동제어를 통해 유튜브 페이지에 접속하고 원하하는 검색어를 입력하여 검색 후, 100개 이상의 영상 제목과 조회수를 수집하시오.
- 수집할 정보는 100개 이상의 영상 제목과 조회수이다.
- pandas의 DataFrame형태로 결과를 출력하여야 한다.
- CSV파일로 한글이 깨지지 않게 저장할 수 있는 코드를 작성하여야 한다.
# 코드를 실행했을 때 100개 이상의 영상이 출력되어야 한다.
# 조회수 크롤링 시 업로드 날짜가 아닌 조회수만 출력되어야 한다.

url = 'https://www.youtube.com/'
driver = wb.Chrome()
driver.get(url)
input_search = driver.find_element_by_id('search')
input_search.send_keys('아이유')
input_search.send_keys(Keys.ENTER)
#페이지 한 400번만 내릴게요
from selenium.webdriver.common.keys import Keys
body = driver.find_element_by_tag_name('body')
for i in range(400):
body.send_keys(Keys.PAGE_DOWN)문제와 같이 유튜브에 특정 검색어를 입력하고 해당 정보에 대한 동영상의 정보를 가져오는 문제.
우선 나는 아이유 를 검색하였다.
- get 명령어를 통해 유투브 페이지를 가져오고
- 아이유 라는 정보를 페이지에 보내고.
- Keys.ENTER 라는 명령어를 통해 검색을 수행
- 페이지의 동영상 정보를 100개 이상 가져오기 위해서는 스크롤을 내려야 함.
- 때문에, PAGE_DOWN 명령어를 통해 400번 정도 내리도록 작업을 수행.
title = driver.find_elements_by_class_name('yt-simple-endpoint.style-scope.ytd-video-renderer')
tes = driver.find_elements_by_css_selector('#metadata-line>span:nth-child(1)')
title_list=[]
for i in title:
title_list.append(i.text)
view_cnt_list = []
for i in tes:
if i.text=='':continue
view_cnt_list.append(i.text)title이란 변수와 tes란 변수에 각각 동영상 제목과 조회수 정보를 가져왔다.
- 정보를 가져오는데는 find_element_by 명령어를 사용하였다.
- 희안하게... 아이유 Page 정보를 가져올 때 동영상 제목은 정상적으로 가져왔으나, 조회수 정보의 경우 Page와 일치하지 않았다. 어째서인지 모르겠으나, 각 List의 첫번째 정보가 동영상은 맞으나, 조회수는 다름.
- 위와 관련하여 수일 후에 다시 시도해보니 정상적으로 같은 갯수의 정보를 가져옴.
- 이유에 대한 사항은 아직 밝히지 못한 상태....
dic={'title':title_list,'view_count':view_cnt_list}
import pandas as p
youtube_df = p.DataFrame(dic, index=range(1,len(title_list)+1))
youtube_df.to_csv('youtube_df.csv', encoding='utf-8-sig')그리고 나서 Ditionary 형태로 각 값들을 받고, DF 형태로 만들며, CSV 파일로 저장
'국비교육기관 > 수업' 카테고리의 다른 글
| 19일차_자바기초_이차원배열_메소드_정렬 (0) | 2021.04.08 |
|---|---|
| 18일차_자바_2차원 배열 (0) | 2021.04.07 |
| 16일차_자바기초_배열이란 / 웹크롤링_Gmarket_이미지크롤링 (0) | 2021.04.05 |
| 15일차_자바기초_for_dowhile / 웹크롤링_Selenium (0) | 2021.04.02 |
| 14일차_자바_WHILE / 웹크롤링_영화랭킹_TOMCAT (0) | 2021.04.01 |




댓글